
Содержание
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочены по значению ключа этого индекса. Если в таблице нет кластерного индекса, таблица называется кучей [3] . Некластерный индекс, созданный для такой таблицы, содержит только указатели на записи таблицы. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами. Наиболее частоупотребимы B*-деревья, B+-деревья, B-деревья и хеши.
Последовательность столбцов в составном индексе
Последовательность, в которой столбцы представлены в составном индексе, достаточно важна. Дело в том, что получить набор данных по запросу, затрагивающему только первый из проиндексированных столбцов, можно. Однако в большинстве СУБД невозможно или неэффективно получение данных только по второму и далее проиндексированным столбцам (без ограничений на первый столбец).
Например, представим себе телефонный справочник, отсортированный вначале по городу, затем по фамилии, и затем по имени. Если вы знаете город, вы можете легко найти все телефоны этого города. Однако в таком справочнике будет весьма трудоёмко найти все телефоны, записанные на определённую фамилию — для этого необходимо посмотреть в секцию каждого города и поискать там нужную фамилию. Некоторые СУБД выполняют эту работу, остальные же просто не используют такой индекс.
Производительность
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того, индексы занимают дополнительный объем памяти, поэтому перед созданием индекса следует убедиться, что планируемый выигрыш в производительности запросов превысит дополнительную затрату ресурсов компьютера на сопровождение индекса.
Ограничения
Индексы полезны для многих приложений, однако на их использование накладываются ограничения. Возьмём такой запрос SQL:
SELECT first_name FROM people WHERE last_name = ‘Франкенштейн’; .
Для выполнения такого запроса без индекса СУБД должна проверить поле last_name в каждой строке таблицы (этот механизм известен как «полный перебор» или «полный скан таблицы», в плане может отображаться словом NATURAL). При использовании индекса СУБД просто проходит по B-дереву, пока не найдёт запись «Франкенштейн». Такой проход требует гораздо меньше ресурсов, чем полный перебор таблицы.
Теперь возьмём такой запрос:
SELECT email_address FROM customers WHERE email_address LIKE ‘%@yahoo.com’; .
Этот запрос должен нам найти всех клиентов, у которых е-мейл заканчивается на @yahoo.com, однако даже если по столбцу email_address есть индекс, СУБД всё равно будет использовать полный перебор таблицы. Это связано с тем, что индексы строятся в предположении, что слова/символы идут слева направо. Использование символа подстановки в начале условия поиска исключает для СУБД возможность использования поиска по B-дереву. Эта проблема может быть решена созданием дополнительного индекса по выражению reverse(email_address) и формированием запроса вида:
SELECT email_address FROM customers WHERE reverse(email_address) LIKE reverse(‘%@yahoo.com’); .
В данном случае символ подстановки окажется в самой правой позиции (moc.oohay@%), что не исключает использование индекса по reverse(email_address).
Редкий индекс
Редкий индекс (англ. sparse index ) в базах данных — это файл с последовательностью пар ключей и указателей. [4] Каждый ключ в редком индексе, в отличие от плотного индекса, ассоциируется с определённым указателем на блок в сортированном файле данных. Идея использования индексов пришла от того, что современные базы данных слишком массивны и не помещаются в основную память. Мы обычно делим данные на блоки и размещаем данные в памяти поблочно. Однако поиск записи в БД может занять много времени. С другой стороны, файл индексов или блок индексов намного меньше блока данных и может поместиться в буфере основной памяти что увеличивает скорость поиска записи. Поскольку ключи отсортированы, можно воспользоваться бинарным поиском. В кластерных индексах с дублированными ключами редкий индекс указывает на наименьший ключ в каждом блоке.

Например, если вы хотите ссылки на все страницы в книге, посвященной определенной теме, сначала обратитесь к индексу, в котором перечислены все темы в алфавитном порядке, а затем передается одному или нескольким конкретным номерам страниц.
Индекс помогает ускорить для запросов SELECT и предложения WHERE, но это замедляет ввод данных, с заявлениями UPDATE и INSERT. Индексы могут быть созданы или удалены без влияния на данные.
Создание индекса предполагает заявление CREATE INDEX, которое позволяет назвать индекс, чтобы указать таблицу и какой столбец или столбцы индексировать и указать, является ли индекс в порядке возрастания или убывания.
Индексы также могут быть уникальными, с ограничением UNIQUE, для того, чтобы индекс предотвращал дублирование записей в столбце или комбинации столбцов, на которых есть индекс.
Команда CREATE INDEX
Основной синтаксис CREATE INDEX выглядит следующим образом:
Одноколоночные индексы
Индекс для одного столбца создается на основе только одного столбца таблицы. Базовый синтаксис выглядит следующим образом.
Уникальные индексы
Уникальные индексы используются не только для работы, но и для обеспечения целостности данных. Уникальный индекс не позволяет какие-либо повторяющиеся значения, которые будут вставлены в таблицу. Базовый синтаксис выглядит следующим образом.
Составные индексы
Составной индекс является индексом для двух или более столбцов таблицы. Его основной синтаксис выглядит следующим образом.
Независимо от того, какой создать индекс, для одного столбца или составной индекс, примите во внимание столбец(ы), которые вы можете использовать очень часто в запросе WHERE в качестве условия фильтра.
Если есть только один используемый столбец, индекс должен быть выбран для одного столбца. Если существуют два или несколько столбцов, которые часто используются в предложении WHERE в качестве фильтров, композитный индекс будет лучшим выбором.
Неявные индексы
Неявные индексы – это индексы, которые автоматически создаются на сервере базы данных при создании объекта. Индексы автоматически создаются для первичного ключа и ограничения уникальности.
Команда DROP INDEX
Индекс может быть удален с помощью SQL команды DROP. Следует соблюдать осторожность при удалении индекса, поскольку производительность может либо замедлиться или улучшиться.
Базовый синтаксис выглядит следующим образом:
Вы можете посмотреть пример ограничения INDEX, чтобы увидеть некоторые реальные примеры по индексам.
Когда следует избегать индексов?
Хотя индексы предназначены для повышения производительности работы с базой данных, есть моменты, когда их следует избегать.
Следующие инструкции показывают, когда использование индекса должно быть пересмотрено.
- Индексы не должны использоваться на небольших таблицах.
- Таблицы, которые имеют частые большие операции обновления или вставки.
- Индексы не должны использоваться на колонках, содержащих большое количество нулевых значений.
- Столбцы, которыми часто манипулируют не должны быть проиндексированы.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Многие слышали о том, что индексы в базах данных это весьма полезная штука. Но, одно дело слышать, а другое представлять себе их устройство хотя бы на базовом уровне. Поэтому в рамках данной статьи для начинающих, я рассмотрю этот вопрос, применяя простые и понятные каждому выражения и аналогии из жизни.
Что такое индекс базы данных и зачем он нужен?
Чтобы понять зачем нужны индексы в базе данных и что он собой представляет, сейчас рассмотрим простой пример.
Представьте себе, что у вас есть полочка для книг. При этом изначально эта полочка с книгами пуста. Книги вам то приносят, то уносят, то делают в них какие-то корректировки (к примеру, мемуары или может быть черновики) и тому подобное.
Так как полочка маленькая, то вы как-то не особо задумывались о какой-либо системе классификации, а просто вставляете книги в любые пустые места.
Каждый раз когда-то вам или кому-то необходимо найти определенную книгу, возникает необходимость просматривать все книги с самого начала полочки до первой попавшейся (если нужна только одна книга) или полностью все (если нужно собрать все копии). В принципе, для одной полочки это весьма необременительно.
Теперь, представьте себе, что речь идет не об одной полочке, а об огромном помещении, где находятся тысячи книг.
Тут-то вы и начинаете задумываться о том, что неплохо бы ввести какую-то систему классификации, например, по названию книги. Конечно, полностью сортировать все эти тысячи книг в алфавитном порядке вы не собираетесь, плюс с этим возникло бы куча других вопросов (как добавить книгу в уже заполненную полку и прочие).
Поэтому вы поступаете проще, вы берете каталог, где возможно добавлять листочки. При этом каждую страницу выделяете только под одно название книги, а сами страницы располагаете в каталоге в порядке возрастания названий. Содержание этих страниц весьма просто — вы записываете в каком стеллаже, на какой полке и какой по счету является книга. Если книг несколько, то строчек в этой странице становится несколько.
Таким образом, чтобы найти одну или все нужные книги по названию, вам достаточно открыть этот каталог и быстро пролестнуть до нужной страницы, а затем пройтись по всем указанным стеллажам. При этом для упрощения, вы так же можете первые буквы названий так же индексировать. То есть добавляете наклейку на каждую первую страницу с указанной буквой (таким образом можете сразу перейти, например, к букве «Р», не пролистывая все названия до нее).
Конечно, для поддержки такой системы требуется дополнительное время, но все же оно существенно меньше, чем попытка найти вслепую книгу из тысячи (пара минут против нескольких часов и более).
Так вот, в данном примере, если переносить это в базу данных:
Помещение — это таблица в базе данных. Если чуть проще, то любое скопище однотипных данных (тех же книг), по сути, представляет собой таблицу.
Поиск книги — это sql-запросы получения данных. При этом важно отметить, что сами по себе они не меняются. То есть вам как нужно было найти «Термодинамику», так и осталось нужным найти «Термодинамику». Другое дело, как вы будете это осуществлять — прочесывая тысячи книг или открыв каталог.
Каталог — это и есть упрощенный вариант индекса в базе данных. То есть, индекс это набор дополнительных данных, записанных в удобном виде, который позволяет существенно быстрее осуществлять поиск, хоть и требующий дополнительных усилий для поддерживания его актуальности.
Имя книги (страничка) — это ключ в индексе. То уникальное значение, которое может ссылаться как на одну какую-то запись, так и на несколько. Стоит отметить, что даже если записей для каждого значения будет несколько, это все равно быстрее, чем полный перебор всех данных.
Если суммировать, то можно увидеть, что наличие индекса может быть весьма выгодным. Например, для одной домашней полочки с десятком книг — индекс в общем-то не сильно нужен, а вот когда речь заходит о более больших объемах, то индекс будет весьма полезным.
Так же можно заметить, что добавление индекса не требует того, чтобы сами sql-запросы были переписаны, так как последние являются лишь выражением на упрощенном языке для базы данных. Если продолжить аналогию, то это как попросить кого-то найти вам «Флора и фауна». При этом каким образом и сколько этот кто-то будет искать книгу, будет решать сам этот человек. В данном примере «найти книгу» — это sql-запрос, а этот «кто-то» это база данных.
Какие бывают индексы?
Вообще, в зависимости от типов баз данных, индексы могут быть очень разными и реализоваться за счет специфических математических механизмов. Но, наиболее частым является древовидный индекс, так как поддерживать такой индекс относительно просто и максимальная скорость поиска в нем составляет логарифм по числу максимального количества дочерних узлом от общего количества записей (плюс минус некоторые технические моменты).
Дерево (древовидный индекс) — это специального вида структура, у которой есть корневая вершина и у каждого узла может быть несколько дочерних узлов. При этом каждый узел встречается только один раз и может иметь всего один родительский узел. Выглядит это так:
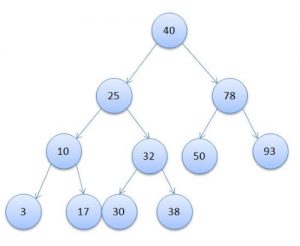
Как видите, очень похоже на перевернутое обычное зеленое дерево, у которого ветки растут не вверх, а вниз.
Максимальное количество дочерних узлов, как вероятно уже догадались по картинке, это то количество дочерних узлов, больше которого у одного узла не может быть.
Теперь поясню откуда берется логарифм. Дело в том, что дерево обычно заполняется по определенным правилам. К примеру, если у узла максимально может быть всего два дочерних узла (так называемое бинарное дерево), то обычно левый дочерний узел имеет значение меньше текущего, а правый большее значение. Поэтому если вам нужно найти, например, число 30 в дереве с рисунка чуть выше, то вам понадобится всего 4 сравнения (40 — 25 — 32 — 30). Именно из-за этой особенности поиска и берется логарифм (так как каждое сравнение сокращает количество проверяемых элементов в два раза). При этом обычно значение логарифма округляют в большую сторону.
Так же отмечу, что такая скорость достигается за счет того, что дерево строится специальным образом, чтобы не возникало таких ситуаций, как на картинке ниже, где максимальная скорость поиска будет сравнима с простым перебором всех записей.
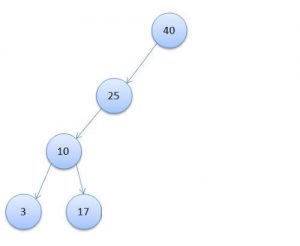
Как видите, чтобы здесь найти запись с ключом «3» понадобится 4 сравнения (40 — 25 — 10 — 3), хотя всего записей 5.
Практически во всех базах данных, существует деление по уникальности:
Уникальный индекс — это такой индекс, у которого все значения встречаются только один раз. Проводя аналогию, когда каждая книга присутствует только в одном экземпляре и никогда названия книг не совпадают.
Неуникальный индекс — это такой индекс, у которого значения могут повторяться. Проводя аналогию, существуют книги с одними и теми же названиями, но разными авторами, или же просто встречаются копии.
Важно отметить, что если для таблицы создается уникальный индекс, то это означает, что при попытке добавить запись со значением, которое уже встречалось, или же изменить значение какой-то записи на существующее, то база данных не позволит сделать такое действие и будет ругаться (выдавать ошибки). В случае же с неуникальным индексом таких проблем нет.
Так же стоит знать, что индексы делятся по количеству входящих в них полей:
Обычные индексы — состоят из одного поля. Здесь, вероятно, все понятно. Обычный каталог страничек.
Составные индексы — строятся по нескольким полям, при этом расположение полей является важным.
Чуть подробнее про составные индексы. Рассмотрим аналогию с теми же книгами. До этого индекс строился только по названию. Теперь же представим, что книги с одинаковыми названиями часто встречаются. В такой ситуации, легко может получится, что страничка каталога будет состоять из координат сотен книг (десятки авторов и у каждого по десять копий). Бегать их всех проверять — так же немалое количество времени. Поэтому вместо того, чтобы страничка просто перечисляла все местонахождения книг, можно сделать так, чтобы странички с именами книг указывали на дополнительные каталоги, где аналогичным образом проиндексированы авторы.
Немного упрощая, поиск будет выглядит примерно так.
1. Вначале вы ищите в каталоге с именами необходимую страничку с названием.
2. Затем в этой страничке смотрите, где находится соответствующий каталог с авторами.
3. Берете этот каталог и уже в нем находите страничку, где указано месторасположение всех книг с этим автором и названием.
При этом важно понимать, что для каждого названия будет создаваться собственный каталог авторов. То есть в обратном порядке, к сожалению, поиск не осуществить. Если же требуется поиск вначале по автору, а уже затем по названиям книг, то необходимо создавать отдельный составной каталог (составной индекс).
Существуют и другие моменты, но чаще всего достаточно знать хотя бы эти базовые знания.