
Содержание
С 2011 года на протяжении многих лет лучшим и самым популярным в мире начальным курсом по Машинному Обучению (Machine Learning) является бесплатный курс Эндрю Ына (Andrew Ng) на Курсере (Coursera). Andrew Ng является VP & Chief Scientist of Baidu; Co-Chairman and Co-Founder of Coursera; co-founded and led Google Brain и an Adjunct Professor (ранее associate professor и Director of the AI Lab) в Stanford University. Курс дает базовое понимание основ Машинного Обучения. Практические примеры и задания используют Octave, что, по мнению многих, является основным недостатком курса. Эндрю Ын отвечает, что для вводного курса Octave проще и понятнее, чем R или Python. Я все же для себя пришел к выводу, что повторить задания на Python просто необходимо, чтобы действительно понять и структуру представленных данных и методы решения. Мои (и не только мои) решения с использованием Python можно найти в моем репозитории на GitHub.
Данная страница создана в помощь рускоязычному сообществу и, возможно, будет полезна при прохождении данного курса, особенно для тех, кто не очень свободно владеет английским языком.
Определение термина Машинное Обучение от Артура Самуэля: "Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed", т.е. "область исследования, которая дает компьютерам возможность учиться без явного программирования".
Определение термина Машинное Обучение от Тома Митчелла: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.", т.е. "говорят, что компьютерная программа учится на опыте E по отношению к некоторому классу задач T и измерению производительности P, если ее производительность при выполнении задач в T, измеренная P, улучшается с опытом E".
Пример: игра в шашки. E = опыт, полученный от многочисленных партий. T = задача игры в шашки. P = вероятность того, что программа выиграет следующую игру.
Целью моделей "Обучение с учителем" (Supervised learning) является поиск параметров (весов), которые минимизируют функцию потерь (Cost function). По размерности независимой переменной $x$ можно выделить однофакторные (univariable) и многофакторые (multivariable) модели. Если независимая переменная $x^<(i)>$ является скалярным значением, то имеем одинарную (univariate) модель. Когда независимая переменная является многомерной, то есть представлена вектором, получаем множественную (multivariate ) модель. В последующих примерах, это поиск $ heta_n$ для каждой независимой переменной $x_n$ с использованием линейной регрессии:
Определение термина Cost function. Дать определение этого термина и показать его отличия от Loss function на русском языке, оказалось достаточно сложной задачей. Поэтому привожу определения на английском:
Loss function is usually a function defined on a data point, prediction and label, and measures the penalty. For example:
- square loss $l(f(x_i| heta),y_i) = left (f(x_i| heta)-y_i
ight )^2$, used in linear regression - hinge loss $l(f(x_i| heta), y_i) = max(0, 1-f(x_i| heta)y_i)$, used in SVM
- 0/1 loss $l(f(x_i| heta), y_i) = 1 iff f(x_i| heta)
eq y_i$, used in theoretical analysis and definition of accuracy
Cost function is usually more general. It might be a sum of loss functions over your training set plus some model complexity penalty (regularization). For example:
- Mean Squared Error $MSE( heta) = frac<1>
sum_^N left (f(x_i| heta)-y_i
ight )^2$ - SVM cost function $SVM( heta) = | heta|^2 + C sum_^N xi_i$ (there are additional constraints connecting $xi_i$ with $C$ and with training set)
Objective function is the most general term for any function that you optimize during training. For example, a probability of generating training set in maximum likelihood approach is a well defined objective function, but it is not a loss function nor cost function (however you could define an equivalent cost function). For example:
- MLE is a type of objective function (which you maximize)
- Divergence between classes can be an objective function but it is barely a cost function, unless you define something artificial, like 1-Divergence, and name it a cost
A loss function is a part of a cost function which is a type of an objective function.
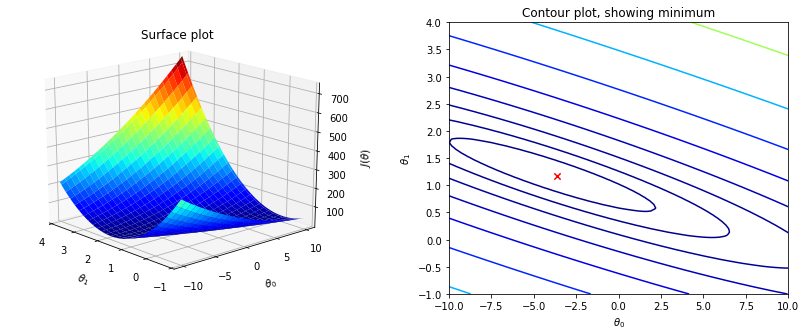
$$J( heta) =frac<1><2m>sumlimits_^
ight)^2$$ где $J( heta) =$ $J( heta_0, heta_1, heta_2, . heta_n)$;
$h_ heta(x)=$ $ heta_0+ heta_1 x_1+ heta_2 x_2+. + heta_n x_n$.
Если сделать так, что $x_0=1$, то $h_ heta(x)$ можно записать как $sumlimits_^
computeCostMulti.m :
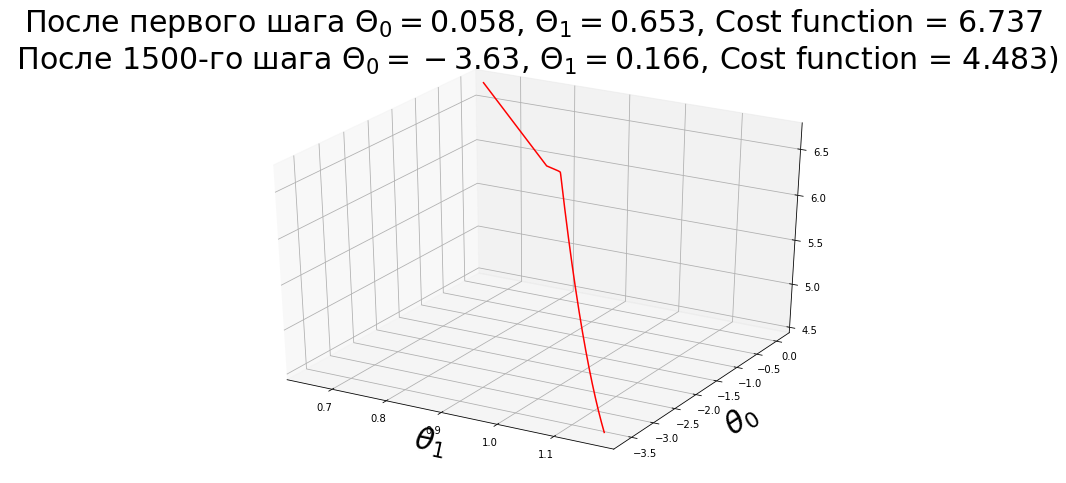
В первом задании первоначальные значения $ heta_0$ и $ heta_1$ равны нулю. Расчет функции потерь (cost function) методом наименьших квадратов на Python с моими комментариями представлен здесь. Про назначение коэффициента $frac<1><2m>$ в функции потерь можно прочитать в ответах на следующие вопросы:
Градиентный спуск
Определение термина Gradient descent (Градиентный спуск) — метод нахождения локального экстремума (минимума или максимума) функции с помощью движения вдоль градиента. $$ heta_j := heta_j — alpha frac<partial> <partial heta_j>J( heta)$$ где $j=0, 1, 2. n$, а $n$ — количество шагов, необходимых для вычисления оптимального значения $ heta$;
$alpha$ — шаг метода Градиентный спуск, скорость обучения. Основное правило: при каждом шаге значение $ heta_j$ должно уменьшаться, поэтому значение $alpha$ не должно быть слишком большим. Но если значение $alpha$ очень маленькое, то метод будет работать очень долго. Поэтому всегда требуется искать золотую середину.
$frac<partial> <partial heta_j>J( heta)$ — частная производная, которая равна $frac<partial> <partial heta_j>frac<1><2m>sum limits_^
ight)^2$ = $2 cdot frac<1> <2m>left(h_ heta(x^<(i)>)-y^<(i)>
ight) cdot frac<partial> <partial heta_j>left(h_ heta(x^<(i)>)-y^<(i)>
ight)$ = $frac<1>
ight) cdot frac<partial> <partial heta_j>left(sum limits_^
ight)$ = $frac<1>
ight) x^<(i)>_j$, в итоге получаем: $$ heta_j := heta_j + alpha frac<1>
ight) x^<(i)>_j$$
Код на Octave для заданий второй недели по определению шага градиентного спуска: theta = theta -((1/m) * ((X * theta) — y)’ * X)’ * alpha.
gradientDescentMulti.m :
Нормализация данных
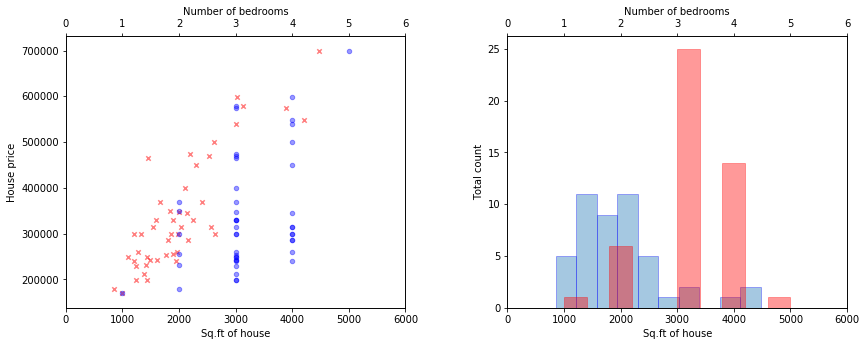
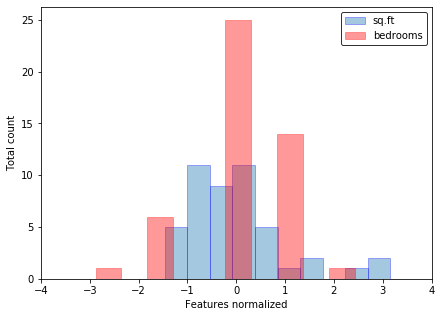
Если features (признаки) отличаются на порядки, то их масштабирование существенно ускоряет работу метода градиентного спуска. Эта процедура называется Feature scaling. Вот пример данных до и после нормализации из задачки второй недели:
featureNormalize.m :
Метод нормальных уравнений. Normal Equation. $$ heta=(X^X)^<-1>X^ y$$
На самом деле обе приведенные выше задачи целесообразнее и проще решать методом номальных уровнений. Вот эти решения. Сравнение методов нормальных уровнений и градиентного спуска для линейной регресси приведено в следующей таблице:
| Градиентный спуск | Метод нормальных уровнений |
|---|---|
| Нужно определить размер шага Градиентного спуска, т.е. коэффициент alpha | Не требуется |
| Нужно определить количество циклов (шагов, итераций) | Не требуется |
| Временная сложность алгоритма $O(kn^2)$ | Временная сложность алгоритма $O(n^3)$, нужно рассчитать обратную матрицу $X^TX$ |
| Хорошо работает, если n — большая величина | Работает медленно, если n — большая величина |
На практике, переход от использования метода нормальных уровнений (Normal Equation) к итерационному процессу (методу Градиентного Спуска), осуществляется когда n превышает 10 000.
normalEqn.m :
Логистическая регрессия
Цель логистической регрессии, как и любого классификатора, состоит в том, чтобы выяснить, каким образом разделить данные, чтобы обеспечить точное предсказание класса данного наблюдения с использованием информации, присутствующей в его признаках (features).
Логистическая функция (сигмоида): $$Largeleft( x
ight) = frac<1><1 + x>>>$$
ее вероятностная интерпритация $
ight) = <
m
>left( <
ight)$.
sigmoid.m :
predict.m :
Функция потерь логистической регрессии (Cost function for logistic regression): $$Jleft( heta
ight) = frac<1>
m
ight),
или более кратко $<
m
ight),y) =$ $- ylog left( <
ight)>
ight) -$ $left( <1 — y>
ight)log left( <1 —
ight)>
ight)$.
В итоге функция потерь логистической регрессии имеет вид:
Здесь подробное объяснение, как взять частную производную фунции потерь логистической регрессии в алгоритме градиентного спуска: $< heta _j>: = < heta _j>- alpha frac<partial ><partial < heta _j>>Jleft( heta
ight)$.
costFunction.m :
Регуляризация
Регуляризация в машинном обучении — метод добавления некоторой дополнительной информации к условию с целью решить некорректно поставленную задачу или предотвратить переобучение.
Функция потерь для линейной регрессии с учетом регуляризации




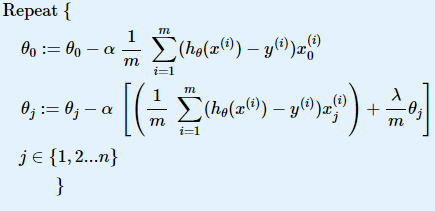
costFunctionReg.m :
Неделя 4. Нейронные сети. Основы.
Код для lrCostFunction.m такой же как и в costFunctionReg.m из предыдущего урока.
Попробуйте запустить следующие примеры кода в Octave перед решением задач этой недели:
predictOneVsAll.m :
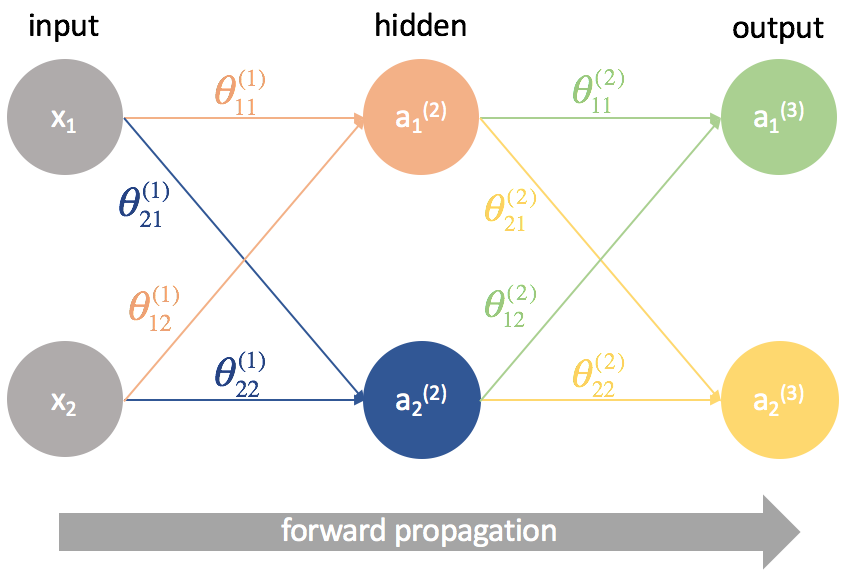
Сети прямого распространения (Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
predict.m :
Неделя 5. Нейронные сети. Cost Function и Метод обратного распространения ошибки (англ. backpropagation).
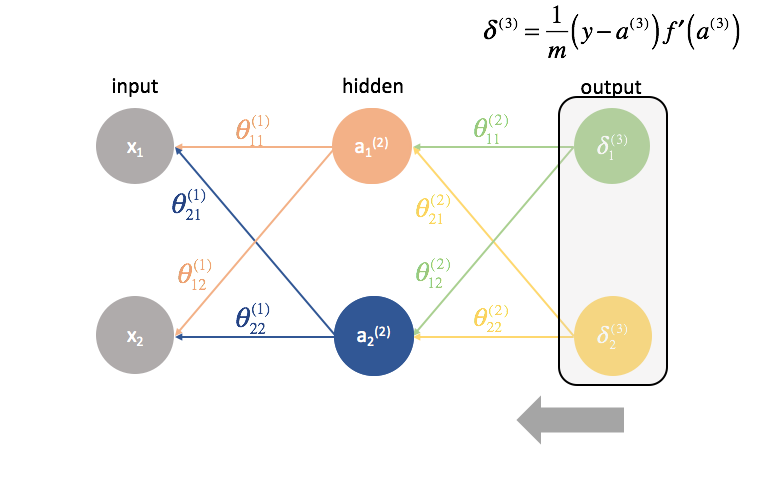
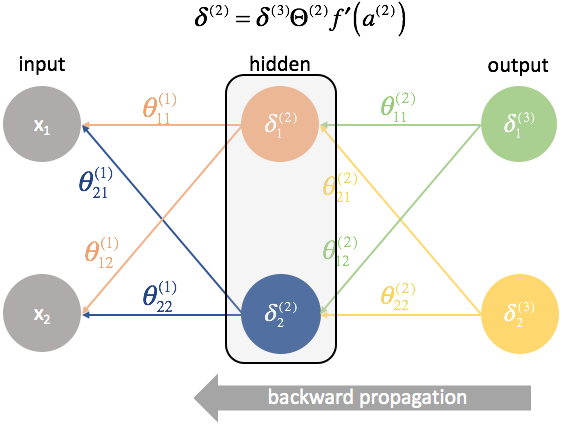
Функция потерь для нейронной сети:

Функция потерь для данной задачи, где нейронная сеть состоит из одного внутреннего слоя:
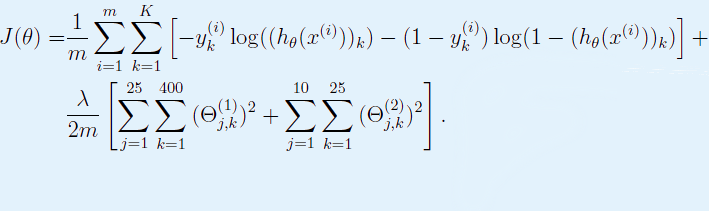 Дополнительные ресурсы для лучшего понимания:
Дополнительные ресурсы для лучшего понимания:
Добрый день!
С чего начать обучение машинному обучению, учитывая что опыта в данной сфере — 0?
Если данная область имеет много направлений, хотелось бы углубиться в AI.
Есть-ли какие-то блоги и книги (желательно на русском языке)?
Так же желательно, что-бы примеры в статях / книге были на одном из данных языков (в порядке убывания):
* JS
* Python
* Java
* Ruby
* C
R, Prolog и т.п. — не интересуют, так как это узконаправленные языки.
- Вопрос задан более трёх лет назад
- 27404 просмотра


sim3x: начал с поиска готовых библиотек на JS и изучением их кода, а так же прочел пару статей на хабре (из которых узнал что DL это круто, и по сути дела — все, так как материал был расчитан на уровень выше начального.)
https://github.com/harthur/brain — JS либа, была еще одна, но мне она показалось сложнее для начала.
Т. Сегаран — программируем коллективный разум. Там есть некоторые методы машинного обучения. Сама книжка смесь вэба и Data Mining. Python
В этих двух книгах теория:
Питер Норвиг. Искусственный интеллект: современный подход
Книга П.С. Романов. Основы искусственного интеллекта
Библиотека scikit-learn с реализованными алгоритмами из книг выше. Python
А также пригодится ( на более поздних этапах )
Козлов М.В., Прохоров А.В. Введение в математическую статистику. — М.: Изд-во МГУ, 1987.
Боровков А.А. Математическая статистика. Оценка параметров, проверка гипотез. — М.: Наука, 1984
Боровков А.А. Математическая статистика. Дополнительные главы. — М.: Наука, 1984.
На ранних этапах желательно знать курс теорвера и матстатики из школы. Что такое вероятность, дисперсия величины и т.д — иногда используются эти понятия. Особенно широко в генетических алгоритмах

Вчера я закончил курс по нейросетям от Andrew Ng. Записался на него не раздумывая, т. к. курс Machine Learning от Andrew был безоговорочно лучшим по этой теме. Ниже — мои впечатления спустя полгода и 3 исписанных лекциями тетради.

Я начинал этот курс почти ничего не зная про современные нейросети. В университете у нас был теоретический курс по Dense Neural Networks, но рассказывался он скорее с позиции “Вот такими забавными вещами занимались люди в 80х, пока не поняли, что это тупиковая ветвь науки”. В 2003–2005 годах это еще была распространенная позиция.
Все, что я пишу ниже, надо рассматривать с этой отправной точки. Для человека “в теме”, специализация вряд ли будет сильно полезной.
- Andrew Ng явно стремится дать понимание и развить интуицию на предмет того, что такое нейронные сети. Это выражается в том, что для всех алгоритмов, которые применяются в курсе, подробно разбираются принципы работы, плюсы, минусы, а также промышленное применение данного алгоритма. Это очень круто еще и потому, что у Andrew опыт промышленного применения есть.
Тут надо отметить, что у Udacity, как правило, подход ровно обратный — дается много знаний про применение инструментов и почти ничего про их внутреннюю логику. На мой взгляд, в DL — это тупиковый путь. Но курсов по DL на Udacity я не слушал, это вречатления от их курсов по ML.
- Курс именно про сети, а не про Tensorflow, Keras или еще какую-нибудь библиотеку. После окончания специализации остается понимание, что и как работает, которого достаточно, чтобы, например, читать научные статьи по нейросетям.
- В рамках полугодового курса рассматриваются обычные нейросети, сверточные модели и рекуррентные нейросети, что покрывает почти все современные типы нейросетей. Не покрыты остались GANN, но, как я понимаю, сейчас это cutting edge, с которым еще надо научиться работать. Плюс, для их обучения нужны мощности недоступные простым смертным
- В отличие от курса про машинное обучение, все задания — на Python, никакого GNU Octave и Matlab. За это огромное спасибо. До сих пор не представляю, кто пользуется Octave и Matlab, когда есть R и Python.
Что не понравилось
Поскольку я был, кажется, во втором или третьем потоке от запуска курса, было много шероховатостей. Иногда неправильно работали домашние задания, иногда в лекциях идет несколько дублей. Иногда сама Coursera генерит баги в ноутбуках и слушателю сложно понять на чьей стороне проблема.
Поддержки студентов в Coursera просто нет, деньги платятся за сертификат, а не за решение проблем. Это сильно выводит из себя даже менторов на форуме, которые иногда срываются и начинают ругаться на работников Coursera сами.
- К сожалению, курс не дает именно практических навыков в плане работы с современными библиотеками для нейронных сетей (Keras/TF/…). Я не считаю это минусом, т. к. за 10 минут чтения документации можно во всем этом разобраться. С теорией же такой фокус не получится, а мне не хватало именно её. Тем не менее, на форуме многие студенты жаловались на то, что их не обучают Keras
- К сожалению, начиная со сверхточных сетей, курс опирается на предобученные алгоритмы. Например, в YOLO (распознавание объектов) или задании по распознаванию голоса на основе LSTM практические задания — это дообучение сетей, а не обучение их с нуля. Это нормальное решение, т. к. обучение с нуля требует много ресурсов и индустрия скорее выступает за transfer learning, но было бы прикольно в рамках факультатива попробовать это сделать. Я в итоге делал примитивный подход к обучению с нуля сам
- Реализаций трудных алгоритмов также не будет — YOLO и word2vec используются как питоновские импорты. Это тоже соответствует практикам индустрии, но я ради интереса также пробовал сделать сам
- Andrew рассказывает про то, чем занимается сам. В Ba >Если резюмировать, мне курс дал именно то, чего я хотел — базу на основе которой можно работать. Этой базы недостаточно, чтобы пойти и начать выигрывать соревнования на Kaggle, но достаточно, чтобы участвовать в них, делать интересные проекты и продолжать учиться области. Если у вас есть желание разобраться в том, как работать с нейросетями — курс отличный.