
Содержание
Одна из самых перспективных наук о компьютерах и программах – компьютерное зрение. Его смысл заключается в способности ПК к распознанию и определению сути картинки. Это важнейшая область в искусственном интеллекте, включающая сразу несколько действий: распознание содержимого фотографии, определение предмета и его классификация или генерация. Поиск объектов на картинке, скорее всего, является важнейшей областью компьютерного зрения.
Определение вещей или живых существ на фотографии активно используется в следующих сферах:
- Поиск автомобилей;
- Система распознания людей;
- Поиск и подсчёт количества пешеходов;
- Усиление системы безопасности;
- Создание беспилотных автомобилей и т. д.
Сегодня удалось разработать много методов для поиска объектов, которые применяются в зависимости от целевой области. В этой сфере, как и в других направлениях использования ИТ-технологий, многое напрямую зависит от программиста. Это отличный инструмент для творчества, с которым «творение» может получить собственный ум. Как использовать интеллект программы уже зависит от творческого мышления разработчика.

Технология действительно перевернула представление об искусственном интеллекте. В дальнейшем она стала основой для следующих методов R-CNN, Fast-RCNN, Faster-RCNN, RetinaNet. Среди них и высокоточные, быстрые методы — SSD и YOLO. Для применения перечисленных алгоритмов, в основе которых глубокое обучение, требуется наличие глубоких познаний в математике и доскональное понимание фреймворков.
Начнем
Рассмотрение советов следует начинать с функциональной библиотеки ImageAI , написанной на Python. Данный фреймворков позволяет с лёгкостью интегрировать инновационные достижения в сфере компьютерного зрения в уже разработанные или новые программы.
Установка Python
Без инсталляции Python 3 здесь не обойтись. Нужно всего лишь загрузить файл с оф. сайта и запустить процесс установки.
Создание зависимостей
Сейчас самое время для того, чтобы посредством pip установить зависимости. Принцип создания команды прост: pip install и название библиотеки (основные фреймворки описаны в списке ниже). Как это выглядит:
Какие фреймворки нужно добавить:
Просмотреть все фреймворки и команды для их установки вы можете на официальном сайте с документацией по ImageAI .

Retina Net
Теперь стоит скачать файл для модели Retina Net. Он участвует в процессе идентификации объектов на изображениях.
Как только зависимости установлены, уже есть возможность написать первые строки кода для вычисления предметов на картинках. Следует создать файл FirstDetection с расширением .py . В созданный файл следует вставить код из следующего раздела. Ещё нужно скопировать файл из модели Retina и добавить картинку для обработки в папку с файлом Python.
Тестирование
Создайте файл и разместите в нем следующий код:
Осталось запустить код и ожидать появление результатов работы в консоли. Дальше следует пройти в каталог, где установлен файл FirstDetection.py . Здесь же должна появиться новая фотография или несколько. Чтобы лучше понимать, что произошло, следует открыть изначальную и новую картинку.
Время рассмотреть принцип работы кода:
Описание строк:
- 1 строка: перенос ImageAI и класса для поиска предмета;
- 2 строка: импорт Python os;
- 4 строка: создание переменной, в которой указывается путь к директории с файлом Python, RetinaNet, моделью и образом.
Описание строк:
- 1 строка: объявление нового класса для поиска объектов;
- 2 строка: установка типа модели RetinaNet;
- 3 строка: указание пути к модели RetinaNet;
- 6 строка: загрузка модели внутрь класса для поиска;
- 8 строка: вызов функции обнаружения (распознавания объектов) и запуск парсинга пути начального и конечного изображений.
ImageAI имеет поддержку массы различных настроек для поиска объектов. Например, можно настроить извлечение всех найденных объектов во время обработки картинки. Класс поиска способен создать отдельную папку с названием image, а затем извлечь, сохранить и вернуть массив с путём ко всем объектам.
Видео обзор
Для более детального рассмотрения библиотеки советуем просмотреть видео обзор этой библиотеки. В ходе видео будет показано не только распознавание объектов на фото, но также вы узнаете про рассмотрение объектов на видео.
Ссылки из видео:
В ходе урока было создано распознавание объектов на видео. Код приведен ниже:
Заключение
В конце советов по глубокому изучению следует добавить небольшую выборку из самых полезных функций ImageAI, ведь её возможности выходят далеко за пределы обычного обнаружения объектов:
- Установка порога минимальной вероятности: стандартные настройки исключают из выборки все объекты с вероятностью до 50% . Они даже не записываются в лог. При желании можно изменить в большую или меньшую сторону вероятности для определённых случаев;
- Особые настройки обнаружения: с помощью класса CustomObject, есть возможность попросить приложение передавать информацию об определении некоторых уникальных объектов;
- Скорость поиска: существует возможность вручную снизить время, которое затрачивает приложение для сканирования фотографии. Есть 3 режима работы: fast, faster, fastest;
- Входящие типы: поддерживает указание в качесиве пути картинке – Numpy-массива, а также файлового потока;
- Выходные типы: можно установить, чтобы функция detectObjectsFromImage возвращала картинки файлом или массивом Numpy.
Конечно, охватить всё компьютерное зрение нереально даже за целую книгу, но основные понятия, надеемся, мы смогли донести.
Яндекс Алиса и другие приложения научились распознавать картинки и фото с камеры, и делать с ними различные полезные действия.
Сейчас уже существует довольно много мобильных приложений, которые распознают фотографии для получения некоторой полезной информации о людях или объёктах на нём. Одно из таких приложений – Facer, показывает на кого из знаменитостей вы похожи, используя алгоритмы на основе нейронных сетей.



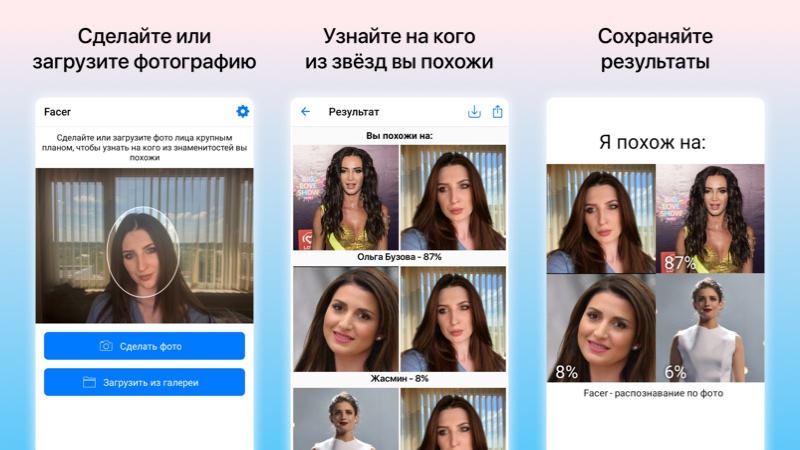
Загружаете фото лица крупным планом и через пару секунд вы видите трёх знаменитостей, на которых вы похожи, с указанием процента сходства. Среди похожих на себя звёзд можно встретить российских и зарубежных музыкантов, актёров, блогеров или спортсменов. Приложение Facer можно скачать по ссылкам: на Android и iOS.
У компании Яндекс тоже есть функции распознавания изображений, они встроены в их голосового помощника. Алиса научилась искать информацию по фотографиям с камеры или любым другим картинкам, которые вы ей отправите. На основе загруженного изображения помощник может сделать некоторые полезные действия. Эти новыми функциями можно воспользоваться в приложении Яндекс и Яндекс.Браузер.
Содержание
Где скачать Алису с поиском по картинкам
Голосовой ассистент Алиса встроен в приложение под названием «Яндекс». Скачать приложение для Android и iOS можно по этим ссылкам:




Как включить поиск по картинкам в Алисе
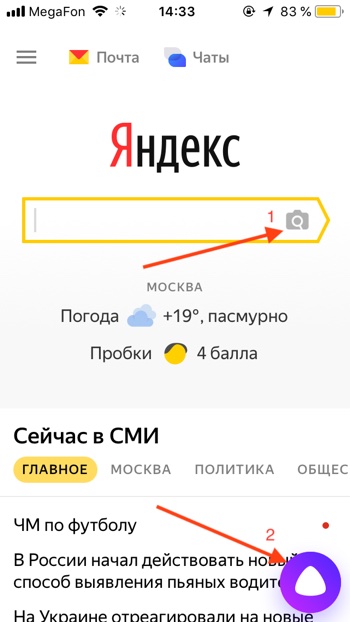
- Чтобы открыть Алису нажимаем на красный значок приложения «Яндекс».

- Первый способ открыть функцию распознавания изображений: нажимаем на серый значок фотоаппарата с лупой в поисковой строке и переходим к шагу 4. Второй способ: нажимаем на фиолетовый значок Алисы или говорим «Привет, Алиса!» если у вас включена голосовая активация.
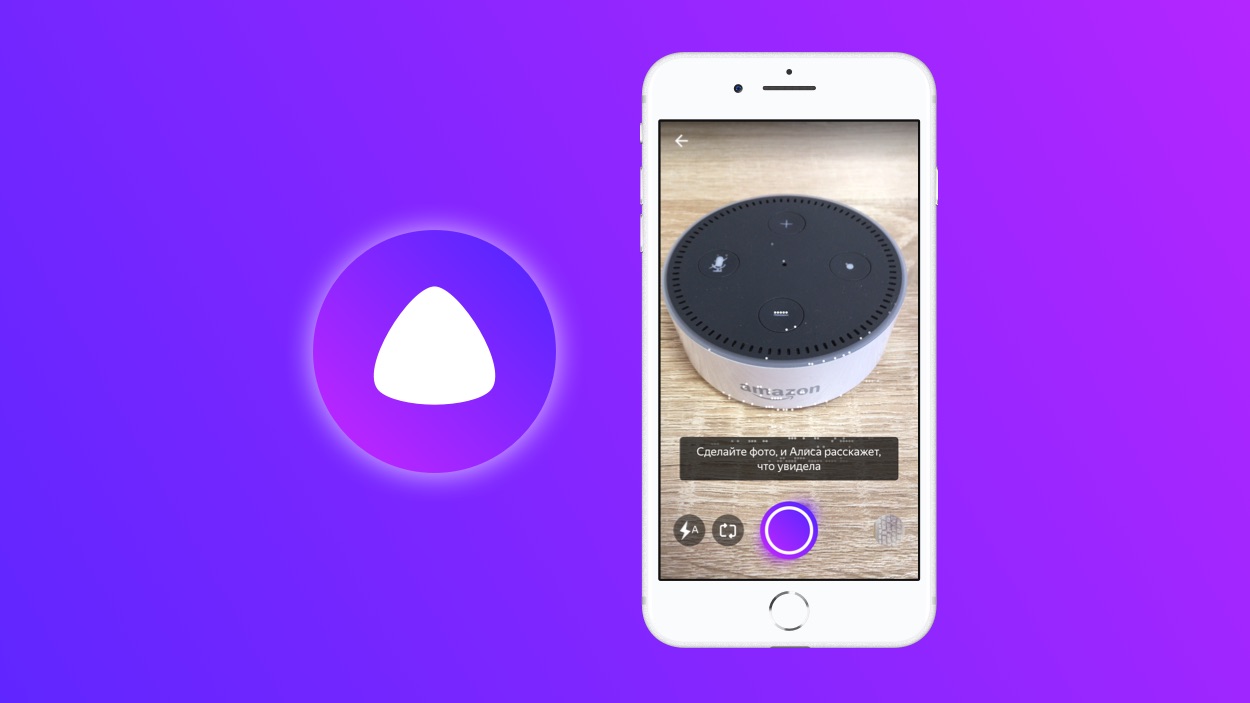
- Откроется диалог (чат) с Алисой. Нужно дать команду Алисе «Распознай изображение» или «Сделай фото». Также вы можете нажать на серый значок фотоаппарата с лупой.
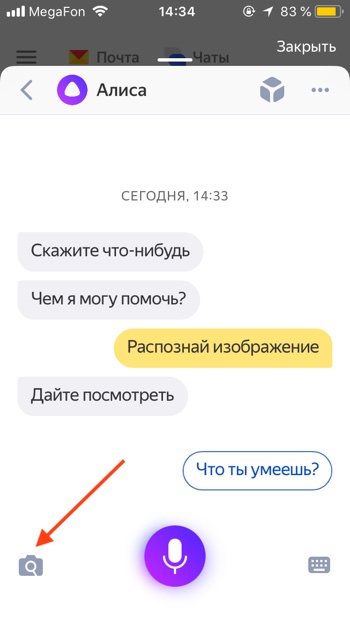
- Приложение попросит доступ к камере вашего мобильного устройства. Нажимаем «Разрешить».
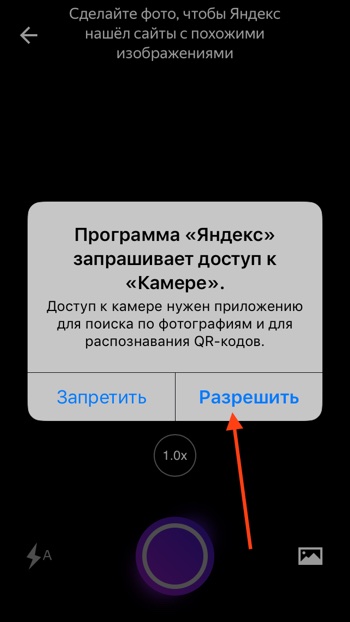
- Откроется режим съёмки. Здесь вы можете загрузить изображение из вашей галлереи или сделать новый снимок прямо сейчас. Нажмите на фиолетовый круг, чтобы сделать снимок.

- Алиса распознает объект на изображении.
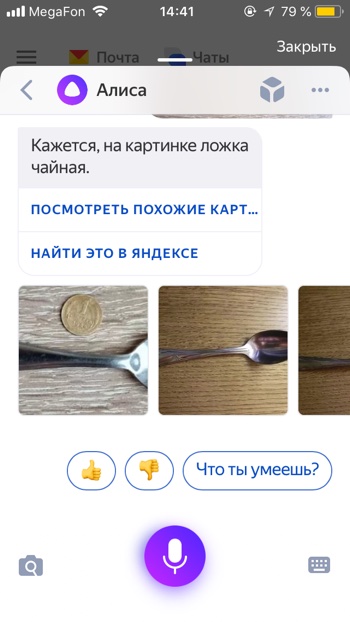
- Давайте попробуем загрузить фотографию из памяти, т.е. галереи вашего iPhone или Android. Нажимаем на иконку с фотографией.

- Алиса попросит доступ к вашим фотографиям. Нажимаем «Разрешить».
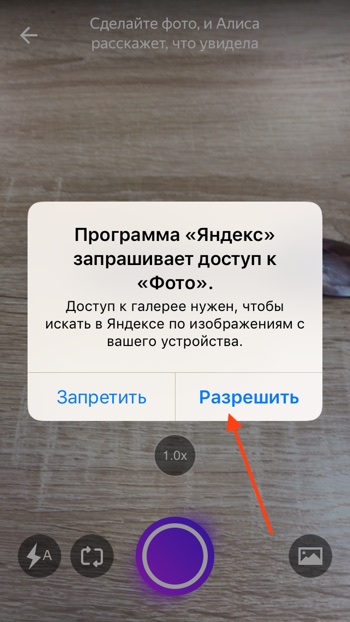
- Выбираем фотографию.
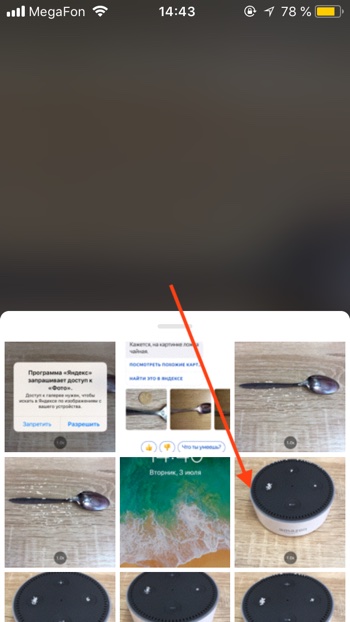
- Через некоторое время фотография загрузится на сервера Яндекса и Алиса вам скажет, на что похоже загруженное изображение. В нашем случае мы загрузили фотографию умной колонки Amazon Echo Dot, и Алиса её успешно распознала.
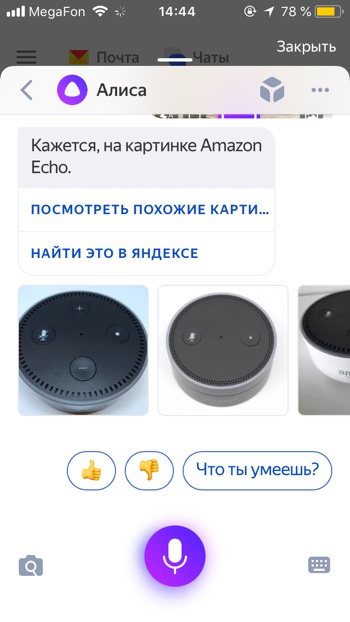
Возможности Алисы по распознаванию изображений и список команд
Помимо общей команды «сделай фото», Алисе можно дать более точную команду по распознаванию объекта. Алиса умеет делать следующие операции с изображениями по соответствующим командам:
Узнать знаменитость по фото
- Кто на фотографии?
- Что за знаменитость на фотографии?
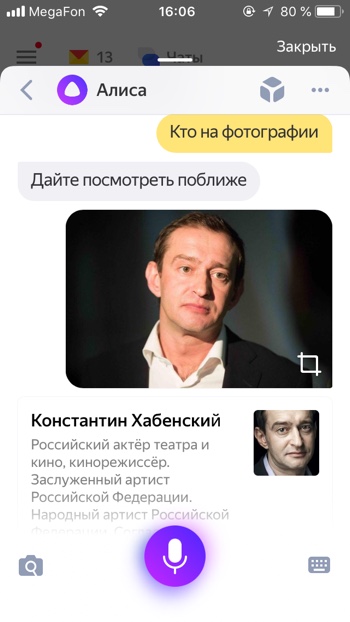
Алиса распознаёт фото знаменитых людей. Мы загрузили изображение актёра Константина Хабенского и Алиса успешно распознала его.
Распознать надпись или текст и перевести его
- Распознай текст
- Распознай и переведи надпись
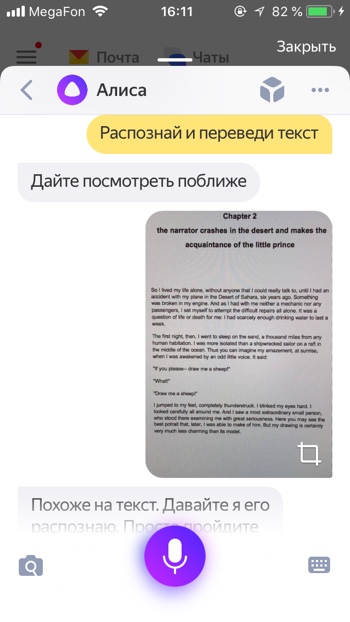
Вы можете загрузить фотографию с текстом и Алиса распознает его и даже поможет его перевести. Для того, чтобы распознать и перевести текст с помощью Алисы необходимо:
— Загрузить фото с текстом.
— Прокрутить вниз.
— Нажать «Найти и перевести текст».
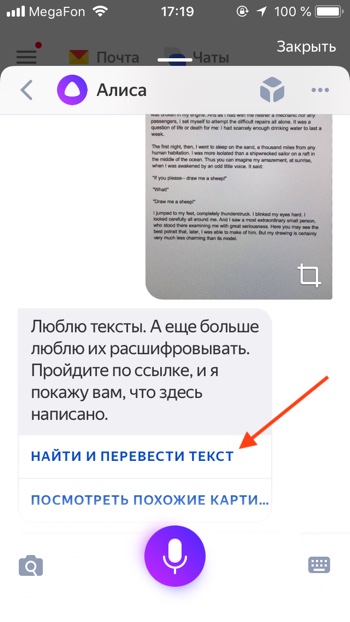
— Откроется распознанный текст. Нажимаем «Перевести».
— Откроется Яндекс.Переводчик с переведённым текстом.

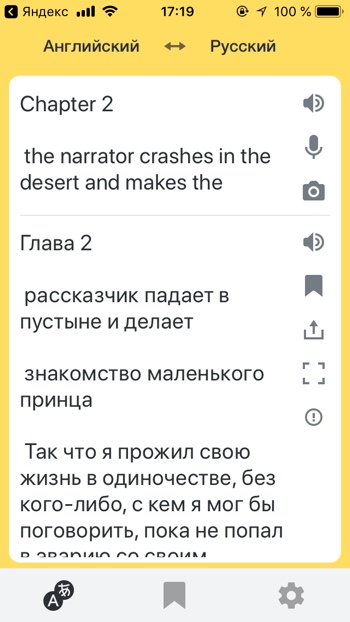
Узнать марку и модель автомобиля
- Определи марку автомобиля
- Распознай модель автомобиля
Алиса умеет определять марки автомобилей. Например, она без труда распознаёт новый автомобиль Nissan X-Trail, в который встроена мультимедийная система Яндекс.Авто с Алисой и Яндекс.Навигатором.
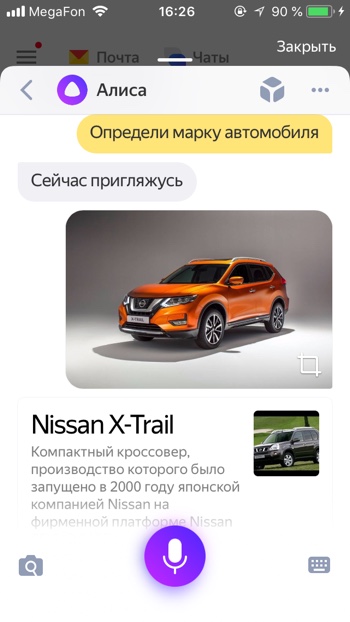
Узнать породу животного
- Распознай животное
- Определи породу собаки
Алиса умеет распознавать животных. Например, Алиса распознала не только, что на фото собака, но и точно определила породу Лабрадор по фото.
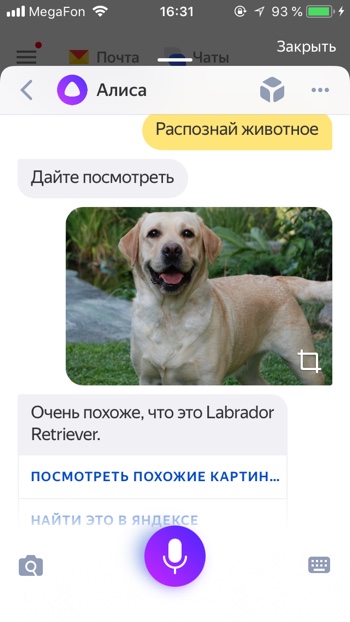
Узнать вид растения
- Определи вид растения
- Распознай растение
Если вы встретили экзотическое растение, Алиса поможет вам узнать его название.
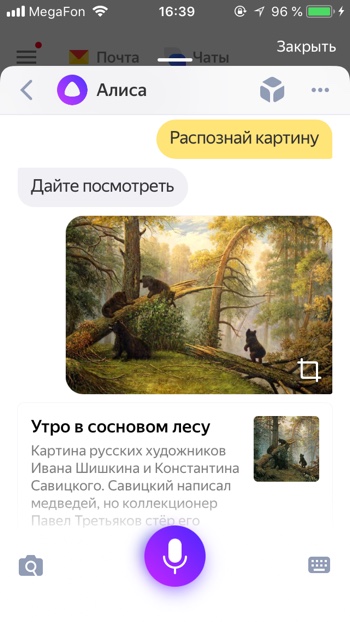
Узнать автора и название картины
- Распознай картину
- Определи что за картина
Если вы увидели картину и хотите узнать её название, автора и описание, просто попросите Алису вам помочь. Картину «Утро в сосновом лесу» художника Ивана Ивановича Шишкина Алиса определяет моментально.
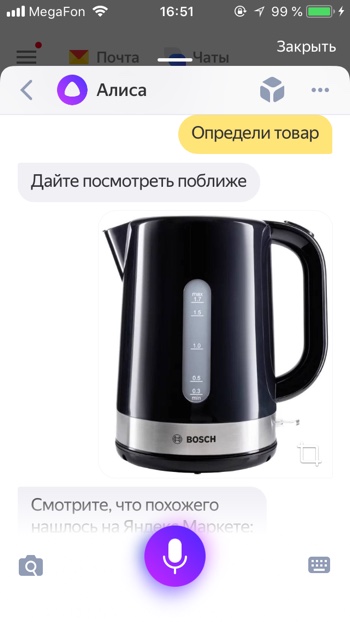
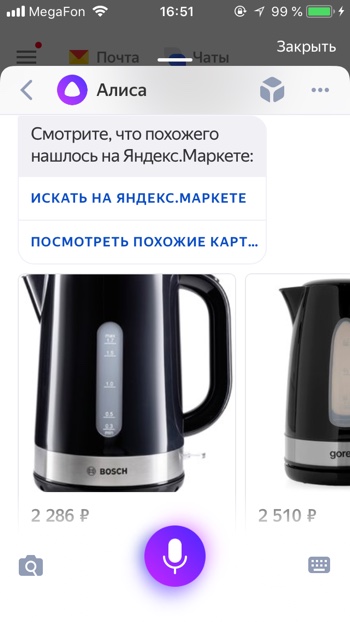
Найти предмет в Яндекс.Маркет
- Определи товар
- Найди товар
Если вы увидите интересный предмет, который вы не прочь были бы приобрести – вы можете попросить Алису найти похожие на него товары. Найденный товар вы можете открыть на Яндекс Маркете и там прочитать его характеристики, или сразу заказать.
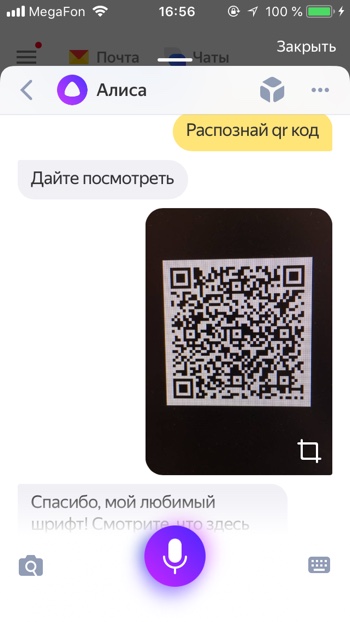
Распознать QR-код
- Определи Кью Эр код
- Распознай Кью Эр код
Алиса пока не так быстро и качественно распознаёт QR коды, нам потребовалось несколько попыток, чтобы успешно распознать QR код.


Попробуйте распознать с помощью Алисы какое-нибудь изображение и напишите о своём опыте и впечатлениях в комментариях.
Яндекс постоянно добавляет новые команды для Алисы. Мы сделали приложение со справкой по командам , которое регулярно обновляем. Установив это приложение, у вас всегда будет под рукой самый актуальный список команд:
В этой статье мы будем разбирать код программы, в которой используется Deep Learning и OpenCV. Её суть: распознавание объектов в реальном времени.
Содержание статьи:
Часть 1: распознавание объектов в реальном времени — работаем с кодом
Пишем код для работы с командной строкой
Добавляем основные объекты
Пишем код для работы с кадрами
«Фильтруем» объекты
Оставшиеся задачи
Часть 2: тестируем распознавание объектов в реальном времени на веб-камере
Ссылки
Этот пост разделён на две части. В первой части мы рассмотрим реализацию распознавания объектов в реальном времени, используем deep-learning и OpenCV, чтобы работать с видео потоками и видеофайлами. В этом нам поможет высокоэффективный класс VideoStream, подробнее о нём читайте здесь.
Оттуда мы возьмём Deep Learning, код для обнаружения объекта и код для измерения FPS.
Часть 1: распознавание объектов в реальном времени — работаем с кодом
Чтобы сделать детектор объектов в реальном времени, нам потребуется:
- Получить доступ к нашей веб-камере/видео потоку.
- Применить распознавание объекта для каждого кадра.
Чтобы посмотреть, как это делается, откройте новый файл, назовите его real_time_object_detection.py и вставьте следующий код:
Мы начали с импортирования библиотек (на строках 2-8). Для этого вам необходим imutils и OpenCV.
Пишем код для работы с командной строкой.
Далее анализируем аргументы командной строки:
- —prototxt : Путь к prototxt Caffe файлу.
- —model : Путь к предварительно подготовленной модели.
- —confidence : Минимальный порог валидности (сходства) для распознавания объекта (значение по умолчанию — 20%).
Добавляем основные объекты.
Затем мы инициализируем список классов и набор цветов:
На строках 22-26 мы инициализируем метки CLASS и соответствующие случайные цвета.
Теперь загрузим модель и настроим наш видео поток:
Загружаем нашу сериализованную модель, предоставляя ссылки на prototxt и модели (строка 30) — обратите внимание, насколько это просто в OpenCV.
Затем инициализируем видео поток (это может быть видеофайл или веб-камера). Сначала запускаем VideoStream (строка 35), затем мы ждём, пока камера включится (строка 36), и, наконец, начинаем отсчёт кадров в секунду (строка 37). Классы VideoStream и FPS являются частью пакета imutils.
Пишем код для работы с кадрами.
Теперь проходим по каждому кадру (чтобы увеличить скорость, можно пропускать кадры).
Первое, что мы делаем — считываем кадр (строка 43) из потока, затем заменяем его размер (строка 44).
Поскольку чуть позже нам понадобится ширина и высота, получим их сейчас (строка 47). Затем следует преобразование кадра в blob с модулем dnn (строки 48 и 49).
Теперь к сложному: мы устанавливаем blob как входные данные в нашу нейросеть (строка 53) и передаём эти данные через net (строка 54), которая обнаруживает наши предметы.
«Фильтруем» объекты.
На данный момент, мы обнаружили объекты в видео потоке. Теперь пришло время посмотреть на значения валидности и решить, должны ли мы нарисовать квадрат вокруг объекта и повесить лейбл.
Мы начинаем проходить циклами через наши detections, помня, что несколько объектов могут быть восприняты как единое изображение. Мы также делаем проверку на валидность (т.е. вероятность) для каждого обнаружения. Если валидность достаточно велика (т.е. выше заданного порога), отображаем предсказание в терминале, а также рисуем на видео потоке предсказание (обводим объект в цветной прямоугольник и вешаем лейбл).
Давайте разберём по строчкам:
Проходим по detections, получаем значение валидности (строка 60).
Если значение валидности выше заданного порога (строка 64), извлекаем индекс лейбла в классе (строка 68) и высчитываем координаты рамки вокруг обнаруженного объекта (строка 69).
Затем, извлекаем (x;y)-координаты рамки (строка 70), которые будем использовать для отображения прямоугольника и текста.
Делаем текстовый лейбл, содержащую имя из CLASS и значение валидности (строки 73 и 74).
Также, рисуем цветной прямоугольник вокруг объекта, используя цвета класса и раннее извлечённые (x;y)-координаты (строки 75 и 76).
В целом, нужно, чтобы лейбл располагался над цветным прямоугольником, однако, может возникнуть такая ситуация, что сверху будет недостаточно места, поэтому в таких случаях выводим лейбл под верхней стороной прямоугольника (строка 77).
Наконец, мы накладываем цветной текст и рамку на кадр, используя значение ‘y’, которое мы только что вычислили (строки 78 и 79).
Оставшиеся задачи:
- Отображение кадра
- Проверка ключа выхода
- Обновление счётчика FPS
Код вверху довольно очевиден: во-первых, выводим кадр (строка 82). Затем фиксируем нажатие клавиши (строка 83), проверяя, не нажата ли клавиша «q» (quit). Если условие истинно, мы выходим из цикла (строки 86 и 87).
Наконец, обновляем наш счётчик FPS (строка 90).
Если происходит выход из цикла (нажатие клавиши «q» или конец видео потока), у нас есть вещи, о которых следует позаботиться:
При выходе из цикла, останавливаем счётчик FPS (строка 92) и выводим информацию о конечном значении FPS в терминал (строки 93 и 94).
Закрываем окно программы (строка 97), прекращая видео поток (строка 98).
Если вы зашли так далеко, вероятно, вы готовы попробовать программу на своей веб-камере. Чтобы посмотреть, как это делается, перейдём к следующему разделу.
Часть 2: тестируем распознавание объектов в реальном времени на веб-камере
Чтобы увидеть детектор объектов в реальном времени в действии, убедитесь, что вы скачали исходники и предварительно подготовленную Convolutional Neural Network.
Оттуда открываете терминал и выполняете следующие команды:
При условии, что OpenCV может получить доступ к вашей веб-камере, вы должны увидеть выходной кадр с любыми обнаруженными объектами. Я привёл примеры результатов в видео ниже:
Заметьте,» что распознаватель объектов может обнаруживать не только меня (человека), но и диван, на котором я сижу и стул рядом со мной. И всё это в реальном времени.
>