
Содержание
Содержание урока
Вопросы и задания
Вопросы и задания
1. За счёт чего удаётся сжать данные без потерь? Когда это сделать принципиально невозможно?
2. Какие типы файлов сжимаются хорошо, а какие — плохо? Почему?
3. Текстовый файл, записанный в однобайтной кодировке, содержит только 33 заглавные русские буквы, цифры и пробел. Ответьте на следующие вопросы:
• какое минимальное число битов нужно выделить на символ при передаче, если каждый символ кодируется одинаковым числом битов?
• сколько при этом будет занимать заголовок пакета данных?
• при какой минимальной длине текста коэффициент сжатия будет больше 1?
4. На чём основан алгоритм сжатия RLE? Когда он работает хорошо? Когда нет смысла его использовать?
5. Что такое префиксный код?
6. В каких случаях допустимо сжатие с потерями?
7. Опишите простейшие методы сжатия рисунков с потерями. Приведите примеры.
8. На чём основан алгоритм JPEG? Почему это алгоритм сжатия с потерями?
9. Что такое артефакты?
10. Для каких типов изображений эффективно сжатие JPEG? Когда его не стоит применять?
11. На чём основано сжатие звука в алгоритме MP3?
12. Что такое битрейт? Как он связан с качеством звука?
13. Какое качество звука принимается за эталон качества на непрофессиональном уровне?
14. Какие методы используются для сжатия видео?
Подготовьте сообщение
а) «Программы для сжатия данных»
б) «Алгоритмы сжатия изображений»
в) «Аудиокодеки»
г) «Видеокодеки»
Следующая страница  Задачи
Задачи
Cкачать материалы урока
Сжатие данных без потерь (англ. lossless data compression ) — класс алгоритмов сжатия данных (видео, аудио, графики, документов, представленных в цифровом виде), при использовании которых закодированные данные однозначно могут быть восстановлены с точностью до бита, пикселя, вокселя и т.д. При этом оригинальные данные полностью восстанавливаются из сжатого состояния. Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
Сжатие данных без потерь используется во многих приложениях. Например, оно используется во всех файловых архиваторах. Оно также используется как компонент в сжатии с потерями.
Сжатие без потерь используется, когда важна идентичность сжатых данных оригиналу. Обычный пример — исполняемые файлы и исходный код. Некоторые графические файловые форматы (например PNG) используют только сжатие без потерь, тогда как другие (TIFF, FLIF или GIF) могут использовать сжатие как с потерями, так и без потерь.
Содержание
Сжатие и комбинаторика [ править | править код ]
Легко доказывается теорема.
Для любого N > 0 нет алгоритма сжатия без потерь, который:
- Любой файл длиной не более N байт или оставляет той же длины, или уменьшает.
- Уменьшает некоторый файл длиной не более N хотя бы на один байт.
Доказательство. Не ограничивая общности, можно предположить, что уменьшился файл A длины ровно N. Обозначим алфавит как Σ <displaystyle Sigma > 
Впрочем, данная теорема нисколько не бросает тень на сжатие без потерь. Дело в том, что любой алгоритм сжатия можно модифицировать так, чтобы он увеличивал размер не более чем на 1 бит: если алгоритм уменьшил файл, пишем «1», потом сжатую последовательность, если увеличил — пишем «0», затем исходную.
Так что несжимаемые фрагменты не приведут к бесконтрольному «раздуванию» архива. «Реальных» же файлов длины N намного меньше, чем 256 N <displaystyle 256^
Метод сжатия без потерь [ править | править код ]
В общих чертах смысл сжатия без потерь таков: в исходных данных находят какую-либо закономерность и с учётом этой закономерности генерируют вторую последовательность, которая полностью описывает исходную. Например, для кодирования двоичных последовательностей, в которых много нулей и мало единиц, мы можем использовать такую замену:
В таком случае шестнадцать битов
будут преобразованы в тринадцать битов
Такая подстановка является префиксным кодом, то есть обладает такой особенностью: если мы запишем сжатую строку без пробелов, мы всё равно сможем расставить в ней пробелы — а значит, восстановить исходную последовательность. Наиболее известным префиксным кодом является код Хаффмана.
Большинство алгоритмов сжатия без потерь работают в две стадии: на первой генерируется статистическая модель для входящих данных, вторая отображает входящие данные в битовом представлении, используя модель для получения «вероятностных» (то есть часто встречаемых) данных, которые используются чаще, чем «невероятностные».
Статистические модели алгоритмов для текста (или текстовых бинарных данных, таких как исполняемые файлы) включают:
Алгоритмы кодирования через генерирование битовых последовательностей:
Читайте также:
- Внецентренное сжатие стержней.
- Информационные процессы (кодирование данных, структуры данных, хранение данных, сжатие данных).
- Лекция 10 Сжатие данных
- Многоступенчатое сжатие
- Мощность потерь в трансформаторе, К.П.Д.
- Основы расчета строительных конструкций, работающих на сжатие
- Отражение в учете сумм недостач, хищений и потерь от порчи ценностей
- Работа древесины на растяжение, сжатие и поперечный изгиб.
- Сжатие видео
- Сжатие данных
- Сжатие движущихся изображений
Сжатие информации
Кодирование делится на три большие группы — сжатие (эффективные коды), помехоустойчивое кодирование и криптография.
Коды, предназначенные для сжатия информации, делятся, в свою очередь, на коды без потерь и коды с потерями.
Кодирование без потерь подразумевает абсолютно точное восстановление данных после декодирования и может применяться для сжатия любой информации.
Кодирование с потерями имеет обычно гораздо более высокую степень сжатия, чем кодирование без потерь, но допускает некоторые отклонения декодированных данных от исходных.
Сжатие с потерями применяется в основном для графики (JPEG), звука (MP3), видео (MPEG), то есть там, где мелкие отклонения от оригинала незаметны или несущественны, а степень сжатия в силу огромных размеров файлов очень важна.
Сжатие без потерь применяется во всех остальных случаях — для текстов, исполняемых файлов, высококачественного звука и графики и т.д. и т.п.
Сжатие необходимо для сокращения длины сообщения и уменьшения времени для его передачи по каналам связи. Все используемые методы упаковки информации можно разделить на два класса: упаковка без потери информации и упаковка с потерей информации.
Сжатие представляет собой предмет выбора оптимального решения. Более эффективный алгоритм требует больше процессорной мощности или времени, необходимого для декодирования информации.
Один из самых простых способов сжатия информации – групповое кодирование. В соответствии с этой схемой серии повторяющихся величин (например, число) заменяются единственной величиной и количеством. Например, аbbbbccdddeeee заменяется на 1a4b2c3d4e. Формат графических файлов PCX использует этот метод.
Простейшие алгоритмы сжатия, называемые также алгоритмами оптимального кодирования, основаны на учете распределения вероятностей элементов исходного сообщения (текста, изображения, файла). На практике обычно в качестве приближения к вероятностям используют частоты встречаемости элементов в исходном сообщении. Вероятность — абстрактное математическое понятие, связанное с бесконечными экспериментальными выборками данных, а частота встречаемости — величина, которую можно вычислить для конечных множеств данных. При достаточно большом количестве элементов в множестве экспериментальных данных можно говорить, что частота встречаемости элемента близка (с некоторой точностью) к его вероятности.
Если вероятности неодинаковы, то имеется возможность наиболее вероятным (часто встречающимся) элементам сопоставить более короткие кодовые слова и, наоборот, маловероятным элементам сопоставить более длинные кодовые слова. Таким способом можно уменьшить среднюю длину кодового слова. Оптимальный алгоритм кодирования делает это так, чтобы средняя длина кодового слова была минимальной, т. е. при меньшей длине кодирование станет необратимым. Такой алгоритм существует, он был разработан Хаффманом и носит его имя. Этот алгоритм используется, например, при создании файлов в формате JPEG.
Методом Хаффмана представляет общую схему сжатия, которая имеет много вариантов. Основная схема – присвоение двоичного кода каждой уникальной величине, причем длина этих кодов различна.
Для того чтобы сформировать минимальный код для каждого символа сообщения, используется двоичное дерево. В основном алгоритме метода объединяются вместе элементы, повторяющиеся наименее часто, затем пара рассматривается как один элемент и их частоты объединяются. Это повторяется до тех пор, пока все элементы не объединятся в пары.
Рассмотрим пример. Пусть дано сообщение abbbcccddeeeeeeeeef.
Частоты символов: а: 1, b: 3, c: 3, d: 2, e: 9, f: 1.
 Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
Наиболее редко используемы в этом примере a и f, так что они становятся первой парой: a – присваивается нулевая ветвь, а f – первая. Это означает, что 0 и 1 будут младшими битами для a и f соответственно. Старшие биты будут получены после построения дерева (рис. 2.4).
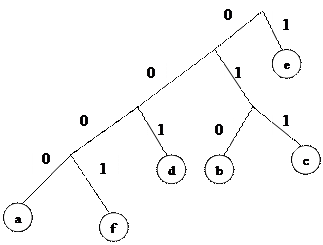 |
Рис. 2.4
Частоты первых двух символов (a и f) суммируются, что дает 2. Поскольку теперь самая низкая частота 2, эта пара объединяется с d (тоже имеет частоту — 2). Исходной паре присваивается нулевая ветвь, а d – первая. Теперь код для a заканчивается на 00, f – на 01, d – на 1. Код для d будет короче на 1 бит. Дерево строится подобным образом для всех символов. Получаем следующие коды:
Исходная последовательность будет закодирована следующим образом: 00000100100100110110110010011111111110001.
Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.Полученная таблица кодов передается приемнику информации и используется при декодировании. По алгоритму Хаффмана наименее распространенные символы кодируются более длинным кодом, наиболее распространенные – коротким.
В результате может быть получена степень сжатия 8:1, что зависит от исходного формата представления информации (1 байт на 1 символ, например, или 2 байта).
Схема Хаффмана работает не так хорошо для информации, содержащей длинные последовательности повторяющихся символов, которые могут быть сжаты лучше с использованием групповой или какой-либо другой схемы кодирования.
Вследствие того, что алгоритм Хаффмана реализуется в два прохода (1 – накопление статистики при построении статистической модели, 2 – кодирование), компрессия и декомпрессия в данном алгоритме – сравнительно медленные процессы.
Другая проблема заключается в чувствительности к отброшенным или добавленным битам. Поскольку все биты сжимаются без учета границ байта, единственный способ, при помощи которого дешифратор может узнать о завершении кода, – достигнуть конца ветви. Если бит отброшен или добавлен, дешифратор начинает обработку с середины кода, и остальная часть данных становится бессмыслицей.
| | | следующая лекция ==> | |
| Параметры семплирования | | | Информационные революции |
Дата добавления: 2014-01-06 ; Просмотров: 372 ; Нарушение авторских прав? ;
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет