
Содержание
Задача удаления концов строчек из (многострочной) строки текста бывает обусловлена, к примеру, когда такая строка прочитана из текстового файла. В этой статье рассмотрим, насколько эффективны различные способы такого удаления.
Символы концов строк
В операционной системе Linux конец строки обозначается символом
(или LF ), а в Windows – двумя символами:
( CR LF ). Обратите внимание, что слеш и идущая после него буква ( r или n ) является ОДНИМ байтом (т.е. 1 байт), хотя для его обозначения требуется ДВА текстовых символа.
Так как файл может быть записан как в Windows, так и в Linux, будем удалять, для надежности, и тот, и другой символы.
Способы удаления концов строк
Рассмотрим наиболее известные пять способов (функции) для удаления концов строк:
1. str_replace(array("
", "
", "
"), », $string[$i]); — для каждой из строчек (записанных в массив) по отдельности, в цикле
2. str_replace(array("
", "
", "
"), », $string); — из всего содержимого файла, как одной строки
3. rtrim($string); — специальная функция для удаления концов строк (а также табуляции, пробелов в конце строк)
4. preg_replace(‘/[
]/’, », $string); — функция удаления концов строк, использующая регулярное выражение для всего содержимого файла, как одной строки
5. preg_replace(‘/[
]/’, », $string); — функция удаления концов строк, использующая регулярное выражение для каждой из строчек (записанных в массив) по отдельности, в цикле
1. Функция str_replace
Эта функция производит замену символов концов строк везде во всей строке. Ее можно использовать как построчно (если текстовый файл был читан при помощи функции file() , которая каждую строчку записывает в соответствующий элемент массива), так и применительно к строке в целом (если файл был считан при помощи функции file_get_contents() в виде единой строки, содержащей, однако, символы
,
).
2. Функция rtrim()
Она предназначена СПЕЦИАЛЬНО для того, чтобы удалять концы строк (т.е. символы
,
) из текстовой строки. Ее можно применить, если файл был считан в построчном режиме. Тогда как, если он считан в виде единой строки – применение ее напрямую невозможно.
3. Функция preg_replace()
Эта функция производит удаление концов строк путем применения регулярного выражения. При работе с содержимым, прочитанным из файла, как с отдельной строкой, эта функция работает на порядок дольше, чем ранее обсуждавшиеся функции. А вот при обработке содержимого файла, как отдельных строк массива, эта функция показывает гораздо лучший результат. Результаты тестирования приведены ниже.
Программный код
Для тестирования различных подходов использовался следующий программный код на РНР:
for($j=0; $j
for ($i = 0; $i
echo ‘time1 (str_replace)=’ . $time1[$j] . ‘ ‘ . ‘time2 (rtrim)=’ . $time2[$j] . ‘
‘;
>
//echo implode(», $file_arr1) .’
‘;
//echo implode(», $file_arr2) .’
‘;
$time1_all=0;
$time2_all=0;
for($j=0; $j
$str = file_get_contents($_SERVER[‘DOCUMENT_ROOT’] . ‘/’ . ‘Sitemap.xml’);
$t = microtime();
for($j=0; $j
$str = file_get_contents($_SERVER[‘DOCUMENT_ROOT’] . ‘/’ . ‘Sitemap.xml’);
$t = microtime();
for($j=0; $j
$file_arr5 = file($_SERVER[‘DOCUMENT_ROOT’] . ‘/’ . ‘Sitemap.xml’);
$file_arr_len5 = sizeof($file_arr5);
for($j=0; $j
echo ‘
time1_all (array, str_replace)=’.$time1_all.’ ‘.’
time2_all (array, rtrim)=’.$time2_all.’ ‘.’
time3_all (string, str_replace)=’.$time3_all . ‘
time4_all (string, preg_replace)=’.$time4_all. ‘
time5_all (array, preg_replace)=’.$time5_all ;
?>
Как видно, этот код последовательно удаляет концы строк из содержимого, считанного из файла. Для примера, взят файл карты сайта Sitemap.xml, находящийся в корневом каталоге сайта. Этот файл имел размер 59,7 кБ, содержал 2250 строчек.
Каждый из четырех способов удаления концов строк, для статистики, применяется 20 раз. Затем результаты усредняются. И вот что получилось:
time1_all (array, str_replace)=0.0055
time2_all (array, rtrim)=0.0027
time3_all (string, str_replace)=0.0021
time4_all (string, preg_replace)=0.0235
time5_all (array, preg_replace)=0.0064 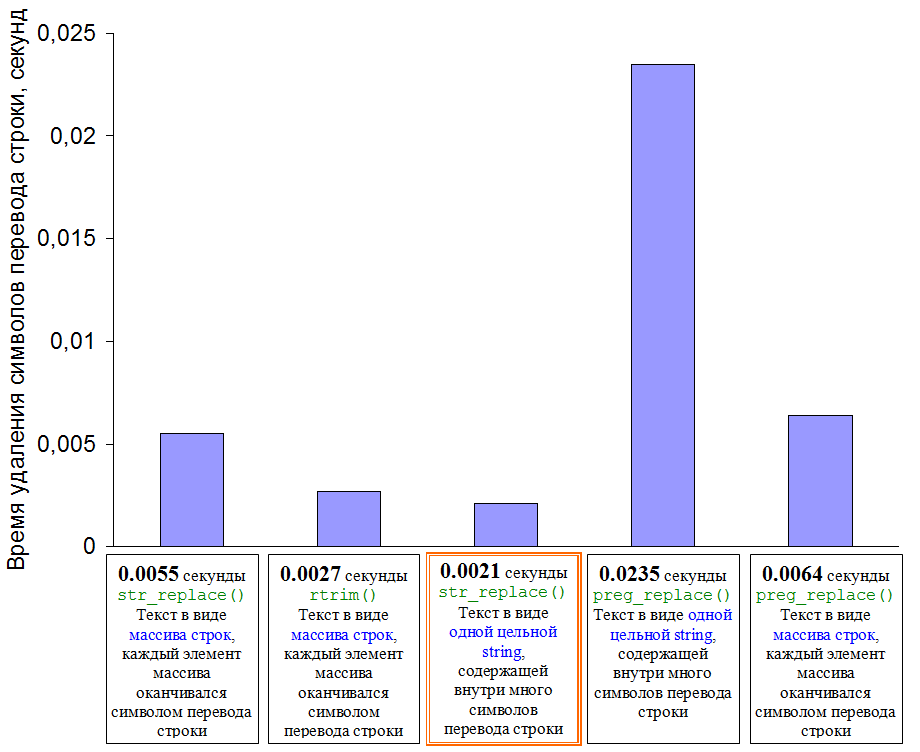
Самым быстрым оказался, как ни странно, третий способ. Это когда файл был прочитан в строку при помощи функции file_get_contents() , а затем концы строчек, содержащиеся в ней, были удалены при помощи str_replace .
Немного медленнее работает функция rtrim() , примененная к содержимому файла, считанного в массив (состоящий из отдельных строчек) и уже из его элементов, в цикле, удалялись концы строчек. По-видимому, несколько более медленная работа функции rtrim() , в данном случае, связана с массивом. А он имел не очень малый размер — состоял из 2250 элементов.
Тогда как в аналогичном цикле, функция str_replace() показала в 2 раза более медленный результат.
Ну, а что касается регулярного выражения, примененного к содержимому файла в целом, тут даже и говорить не приходится: время выполнения увеличилось на порядок! Хотя, при разбиении файла на строчки и создании соответствующего массива, функция preg_replace() работает быстрее. Но, даже и в этом случае – чисто строковые функции (без регулярных выражений) работают быстрее.
Выводы
Итак, наверное, банально, но, все же, стоит отметить:
Обобщение
Отметим, что данные выводы, скорее всего, справедливы не только для языка PHP, но и для многих других аналогичных языков, например, Python, C#, Ruby . Т.е. для высокоуровневых языков. Потому, что в этих языках команды, по сути, представляют собой, всего-навсего, набор готовых скриптов той или иной степени эффективности. Написанных на языке С/С++ .
Поэтому целесообразнее применять именно ту функцию, которая как раз и предназначена для выполнения соответствующей задачи, взамен более универсальной функции. Правда, из этого правила бывают исключения. Как видим, в третьем варианте универсальная функция str_replace() сработала, все-таки, быстрее специализированной rtrim() . Кстати, такой же парадокс наблюдается и для специализированной функции file() : она работает, как ни странно, раза в 2 медленнее, чем пара функций fopen() + explode() .
А вот для программ на С/С++ — разница, видимо, будет не столь заметна.
Что касается регулярных выражений, то, как видно, чем меньше размер строки (на каждой итерации цикла), тем быстрее происходит обработка. По результатам тестирования получилось, что разбиение содержимого, считанного из файла, в массив (построчно) показало гораздо более лучший (в смысле быстроты обработки) результат, по сравнению с обработкой содержимого файла как одной цельной строки (тогда как при использовании str_replace() — все полностью наоборот). При этом, что интересно, время работы функции preg_replace() ненамного выше, чем время работы функции str_replace() , хотя последняя, вроде как, работает с «чистыми» строками, без использования регулярных выражений.
В целом же, можно сделать такой вывод
. Не стоит использовать первую попавшуюся функцию в РНР только потому, что она присутствует в этом языке и кем-то рекомендована. Если, конечно, вебразработчика интересует быстрота работы программы на PHP, равно как и скорость открытия страниц сайта в целом. Если в конкретной ситуации язык дает несколько возможностей для решения одной и той же задачи (т.е. если возможно применить разные функции), то, чтобы сайт функционировал наиболее быстро, следует, увы, тестировать, как работает каждая из функций и выбирать наиболее оптимальную. Да, вывод этот, конечно, банальный. Однако, скорость работы функций РНР в маннуалах не прописана. Да и на форумах компьютерных этот вопрос, зачастую, как-то обходят стороной. Работает мол (как-то там), да и ладно. Так что выход здесь один: практическое тестирование функциональности/скорости. Не обращая внимания на маннуалы.
Понятно, что для небольших сайтов, при обработке сравнительно небольших строк, слабой нагруженности сайта, в самом деле, нет смысла что-то там оптимизировать и вылавливать эти доли секунд. В самом деле, какая разница — выполнится некая операция то ли за 0,002 секунды, то ли за 0,02 секунды? Все равно, мол, очень быстро. Но, по мере развития сайта, по мере роста посещаемости — все эти, казалось бы, мелочи, в итоге, сложившись, могут дать существенное замедление скорости работы сайта. И, как следствие — падение позиций в поисковиках, появление определенных, не особенно приятных, чувств к такому сайту у пользователей. Кто-то в подобной ситуации может начать думать в направлении, мол, более мощного сервера. А лучше бы, в первую очередь, выбирать оптимальные, для каждого случая, функции.
Правда, озвученный выше подход, скорее всего, ОЧЕНЬ не понравится так называемым любителям "командной работы". Ну, это когда "команда" состоит из (бывших) студентов-троечников, каждый из которых является, так сказать, "узким специалистом" (ну, т.е. таким, который освоил лишь что-то одно, да и то — на минимальном уровне). И/или когда принцип работы "команды" — примерно такой: программистам — определенная зарплата (ну, быть может, плюс некие премии), а руководству — все остальные финансы и доходы.
(PHP 4, PHP 5, PHP 7)
trim — Удаляет пробелы (или другие символы) из начала и конца строки
Описание
Список параметров
Можно также задать список символов для удаления с помощью необязательного аргумента character_mask . Просто перечислите все символы, которые вы хотите удалить. Можно указать конструкцию .. для обозначения диапазона символов.
Возвращаемые значения
Примеры
Пример #1 Пример использования trim()
= " These are a few words 🙂 . " ;
$binary = "x09Example stringx0A" ;
$hello = "Hello World" ;
var_dump ( $text , $binary , $hello );
$trimmed = trim ( $text );
var_dump ( $trimmed );
$trimmed = trim ( $text , " ." );
var_dump ( $trimmed );
$trimmed = trim ( $hello , "Hdle" );
var_dump ( $trimmed );
$trimmed = trim ( $hello , ‘HdWr’ );
var_dump ( $trimmed );
// удаляем управляющие ASCII-символы с начала и конца $binary
// (от 0 до 31 включительно)
$clean = trim ( $binary , "x00..x1F" );
var_dump ( $clean );
Результат выполнения данного примера:
Пример #2 Обрезание значений массива с помощью trim()
$fruit = array( ‘apple’ , ‘banana ‘ , ‘ cranberry ‘ );
var_dump ( $fruit );
array_walk ( $fruit , ‘trim_value’ );
var_dump ( $fruit );
Результат выполнения данного примера:
Примечания
Замечание: Возможные трюки: удаление символов из середины строки
Так как trim() удаляет символы с начала и конца строки string , то удаление (или неудаление) символов из середины строки может ввести в недоумение. trim(‘abc’, ‘bad’) удалит как ‘a’, так и ‘b’, потому что удаление ‘a’ сдвинет ‘b’ к началу строки, что также позволит ее удалить. Вот почему это "работает", тогда как trim(‘abc’, ‘b’) очевидно нет.
Смотрите также
- ltrim() — Удаляет пробелы (или другие символы) из начала строки
- rtrim() — Удаляет пробелы (или другие символы) из конца строки
- str_replace() — Заменяет все вхождения строки поиска на строку замены
User Contributed Notes 16 notes
When specifying the character mask,
make sure that you use double quotes
= "
Hello World " ; //here is a string with some trailing and leading whitespace
$trimmed_correct = trim ( $hello , "
" ); // $trimmed_incorrect = trim ( $hello , ‘
‘ ); // print( "—————————-" );
print( "TRIMMED OK:" . PHP_EOL );
print_r ( $trimmed_correct . PHP_EOL );
print( "—————————-" );
print( "TRIMMING NOT OK:" . PHP_EOL );
print_r ( $trimmed_incorrect . PHP_EOL );
print( "—————————-" . PHP_EOL );
?>
Here is the output:
Non-breaking spaces can be troublesome with trim:
// turn some HTML with non-breaking spaces into a "normal" string
$myHTML = " abc" ;
$converted = strtr ( $myHTML , array_flip ( get_html_translation_table ( HTML_ENTITIES , ENT_QUOTES )));
// this WILL NOT work as expected
// $converted will still appear as " abc" in view source
// (but not in od -x)
$converted = trim ( $converted );
// are translated to 0xA0, so use:
$converted = trim ( $converted , "xA0" ); // >
// UTF encodes it as chr(0xC2).chr(0xA0)
$converted = trim ( $converted , chr ( 0xC2 ). chr ( 0xA0 )); // should work
// PS: Thanks to John for saving my sanity!
?>
trim is the fastest way to remove first and last char.
Benchmark comparsion 4 different ways to trim string with ‘/’
4 functions with the same result — array exploded by ‘/’
print cycle ( "str_preg(‘ $s ‘);" , $times );
print cycle ( "str_preg2(‘ $s ‘);" , $times );
print cycle ( "str_sub_replace(‘ $s ‘);" , $times );
print cycle ( "str_trim(‘ $s ‘);" , $times );
print cycle ( "str_clear(‘ $s ‘);" , $times );
function cycle ( $function , $times ) <
$count = 0 ;
if( $times 1 ) <
return false ;
>
$start = microtime ( true );
while( $times > $count ) <
eval( $function );
$count ++;
>
$end = microtime ( true ) — $start ;
return "
$function exec time: $end " ;
>
function str_clear ( $s ) <
$s = explode ( ‘/’ , $s );
$s = array_filter ( $s , function ( $s ));
return $s ;
>
function str_preg2 ( $s ) <
$s = preg_replace ( ‘/((? , » , $s );
$s = explode ( ‘/’ , $s );
return $s ;
>
function str_preg ( $s ) <
$s = preg_replace ( ‘/^(/?)(.*?)(/?)$/i’ , ‘$2’ , $s );
$s = explode ( ‘/’ , $s );
return $s ;
>
function str_sub_replace ( $s ) <
$s = str_replace ( ‘/’ , » , mb_substr ( $s , 0 , 1 )) . mb_substr ( $s , 1 , — 1 ) . str_replace ( ‘/’ , » , mb_substr ( $s , — 1 ));
$s = explode ( ‘/’ , $s );
return $s ;
>
function str_trim ( $s ) <
$s = trim ( $s , ‘/’ );
$s = explode ( ‘/’ , $s );
return $s ;
>
To remove multiple occurences of whitespace characters in a string an convert them all into single spaces, use this:
It is worth mentioning that trim, ltrim and rtrim are NOT multi-byte safe, meaning that trying to remove an utf-8 encoded non-breaking space for instance will result in the destruction of utf-8 characters than contain parts of the utf-8 encoded non-breaking space, for instance:
non breaking-space is "u
$input = "u
$output = trim($input, "u
$output got both "u
if you are using trim and you still can’t remove the whitespace then check if your closing tag inside the html document is NOT at the next line.
there should be no spaces at the beginning and end of your echo statement, else trim will not work as expected.
Trim full width space will return mess character, when target string starts with ‘《’
php version 5.4.27
[EDIT by cmb AT php DOT net: it is not necessarily safe to use trim with multibyte character encodings. The given example is equivalent to echo trim("xe3808a", "xe3x80x80").]
Standard trim() functions can be a problematic when come HTML entities. That’s why i wrote "Super Trim" function what is used to handle with this problem and also you can choose is trimming from the begin, end or booth side of string.
function strim ( $str , $charlist = " " , $option = 0 ) <
if( is_string ( $str ))
<
// Translate HTML entities
$return = strtr ( $str , array_flip ( get_html_translation_table ( HTML_ENTITIES , ENT_QUOTES )));
// Remove multi whitespace
$return = preg_replace ( "@s+s@Ui" , " " , $return );
// Choose trim option
switch( $option )
<
// Strip whitespace (and other characters) from the begin and end of string
default:
case 0 :
$return = trim ( $return , $charlist );
break;
// Strip whitespace (and other characters) from the begin of string
case 1 :
$return = ltrim ( $return , $charlist );
break;
// Strip whitespace (and other characters) from the end of string
case 2 :
$return = rtrim ( $return , $charlist );
break;
Beware with trimming apparently innocent characters. It is NOT a Unicode-safe function:
echo trim ( ‘≈ [Approximation sign]’ , ‘– [en-dash]’ ); // �� [Approximation sig
?>
The en-dash here is breaking the Unicode characters.
And also prevents the open-square-bracket from being seen as part of the characters to trim on the left side, letting it untouched in the resulting string.
If you want to check whether something ONLY has whitespaces, use the following:
if ( trim ( $foobar )== » ) <
echo ‘The string $foobar only contains whitespace!’ ;
>
Simple Example I hope you will understand easily:
// Inserting empty variable;
if( !(empty( $name )) )
<
$sql = "INSERT INTO `users`( name ) VALUE( ‘ $name ‘ );" ;
>
// But is not empty that will be inserted but space
if( !(empty( $name )) )
<
$sql = "INSERT INTO `users`( name ) VALUE( ‘ $name ‘ );" ;
>
// Now that will not be inserted by using trim() function
if( !(empty( trim ( $name ) )) )
<
$sql = "INSERT INTO `users`( name ) VALUE( ‘ $name ‘ );" ;
>
(PHP 4, PHP 5, PHP 7)
trim — Удаляет пробелы (или другие символы) из начала и конца строки
Описание
Список параметров
Можно также задать список символов для удаления с помощью необязательного аргумента character_mask . Просто перечислите все символы, которые вы хотите удалить. Можно указать конструкцию .. для обозначения диапазона символов.
Возвращаемые значения
Примеры
Пример #1 Пример использования trim()
= " These are a few words 🙂 . " ;
$binary = "x09Example stringx0A" ;
$hello = "Hello World" ;
var_dump ( $text , $binary , $hello );
$trimmed = trim ( $text );
var_dump ( $trimmed );
$trimmed = trim ( $text , " ." );
var_dump ( $trimmed );
$trimmed = trim ( $hello , "Hdle" );
var_dump ( $trimmed );
$trimmed = trim ( $hello , ‘HdWr’ );
var_dump ( $trimmed );
// удаляем управляющие ASCII-символы с начала и конца $binary
// (от 0 до 31 включительно)
$clean = trim ( $binary , "x00..x1F" );
var_dump ( $clean );
Результат выполнения данного примера:
Пример #2 Обрезание значений массива с помощью trim()
$fruit = array( ‘apple’ , ‘banana ‘ , ‘ cranberry ‘ );
var_dump ( $fruit );
array_walk ( $fruit , ‘trim_value’ );
var_dump ( $fruit );
Результат выполнения данного примера:
Примечания
Замечание: Возможные трюки: удаление символов из середины строки
Так как trim() удаляет символы с начала и конца строки string , то удаление (или неудаление) символов из середины строки может ввести в недоумение. trim(‘abc’, ‘bad’) удалит как ‘a’, так и ‘b’, потому что удаление ‘a’ сдвинет ‘b’ к началу строки, что также позволит ее удалить. Вот почему это "работает", тогда как trim(‘abc’, ‘b’) очевидно нет.
Смотрите также
- ltrim() — Удаляет пробелы (или другие символы) из начала строки
- rtrim() — Удаляет пробелы (или другие символы) из конца строки
- str_replace() — Заменяет все вхождения строки поиска на строку замены