
Ошибка СУБД:
Microsoft OLE DB Provider for SQL Server: Журнал транзакций для базы данных «ReportServer» заполнен. Чтобы обнаружить причину, по которой место в журнале не может быть повторно использовано, обратитесь к столбцу log_reuse_wait_desc таблицы
sys. databases HRESULT=80040E14, SQLStvr: Error state=2, Severity=11,native=9002, line=1
или
Ошибка СУБД:
Microsoft OLE Provider for SQL Server: The transaction log for database “ReportServer” is full. To find out why space in the log cannot be reused, see the log_reuse_wait_desc column is sys.database
HRESULT=80040E14, SQLSTATE=4 2000, native=9002
это значит, что на диске, где расположен лог транзакций закончилось место и теперь СУБД некуда записывать данные о новых транзакциях. Чаще всего такое происходит, когда не установлено никаких ограничений на размер лога и в MS SQL не создано соответствующих планов обслуживания.
В таком случае нужно уменьшить размер самого файла транзакций (*.ldf), другими словами сделать шринк (сжатие) лога. Для этого можно использовать как запрос, так и сжатие лога вручную.
Рассмотрим сжатие лога транзакций вручную:
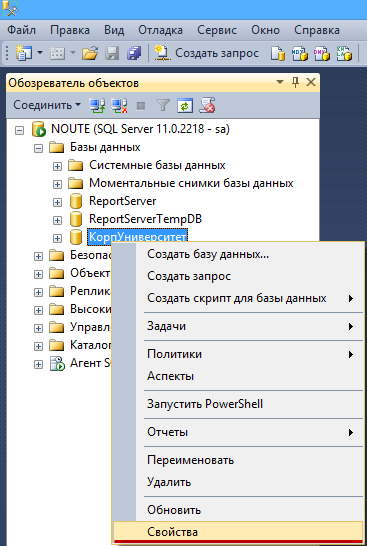
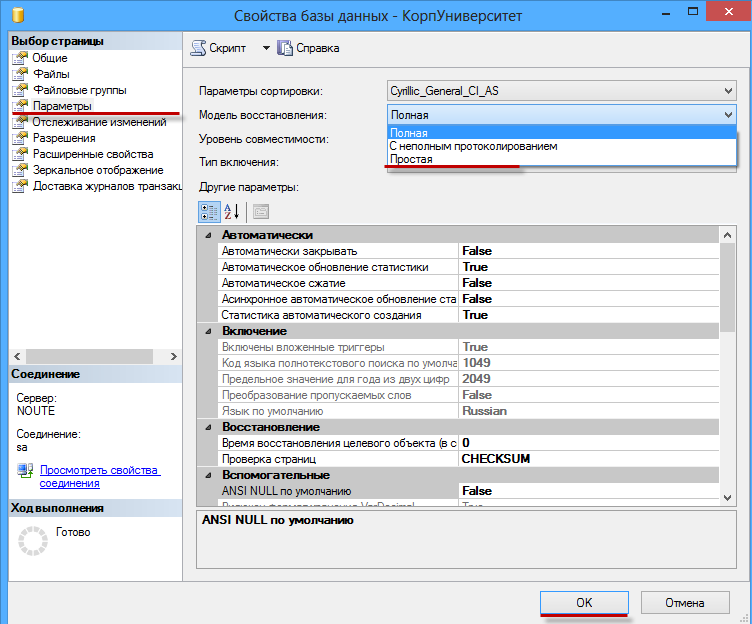
Шаг 1. Установить модель восстановления Простая (Simple). Правой кнопкой на базе — Свойства(Properties)
Выполнить сжатие (Shrink) лога транзакций. Правой кнопкой на базе — Задачи(Tasks) — Сжать(Shrink) — Файлы(Files) 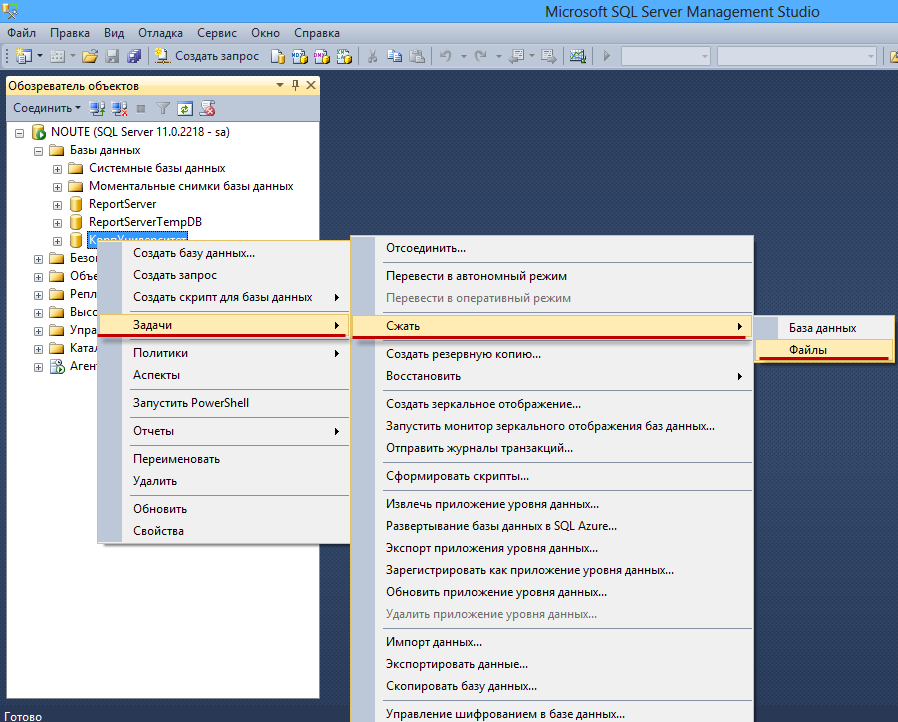
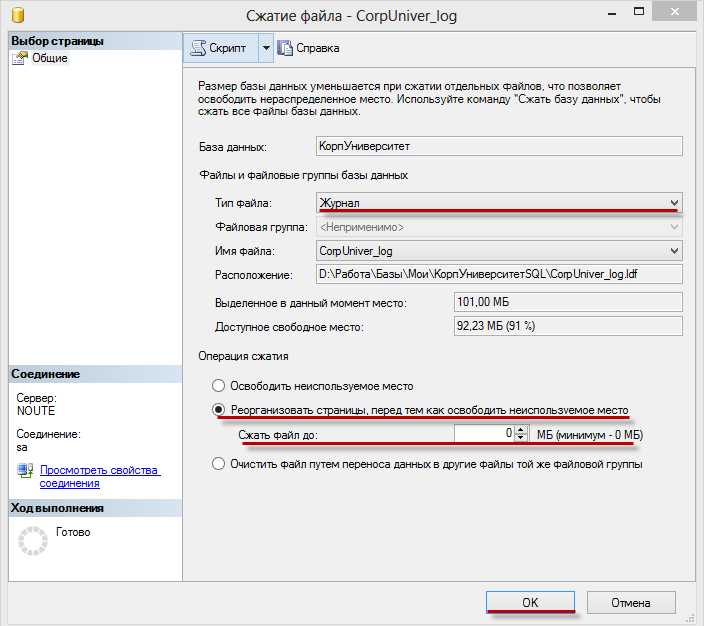
Установить Тип файла(File type) — Журнал(Log) — в Операция сжатия(Shrink action) — выбрать Реорганизовать страницы, перед тем освоить неиспользуемое место(Reorganize pages before releseasing unused space) — Сжать файл (Shrink file to)
указать приемлемый размер лога.
Установить модель восстановления Полная(Full). Правой кнопкой на базе — Свойства(Properties) — Параметры(Options) — 4-й сверху пункт Модель восстановления(Recovery model) — Полная(Full) — OK.
Всегда логи транзакций в MS SQL растут, что может повлечь за собой серьезные проблемы в виде нехватки места на диске. Чтобы этого избежать, в MS SQL Server существует операция сокращения и размера файлов данных и файлов журнала логов (Shrink). Урезание логов производится автоматически, в зависимости от модели восстановления:
• В простой модели (Simple) — после достижения контрольной точки;
• В модели полного восстановления (Full) — после создания backup логов, при условии что со времени предыдущего backup была достигнута контрольная точка.
Но бывают ситуации, когда автоматическое урезание по каким либо причинам не производится и логи занимают все свободное место. Причем происходит это всегда неожиданно и требуется срочно освободить место. В этом случае урезание можно произвести вручную.
Подобная ситуация, как правило, происходит с моделью восстановления Full, при использовании которой лог нельзя обрезать до тех пор, пока в резервную копию не попали все транзакции. Это необходимо для того, чтобы обеспечить наличие непрерывную последовательность номеров (LSN) записей в журнале. Соответственно для урезания надо либо сделать полное резервное копирование БД, либо (что проще и быстрее) временно перевести ее в режим Simple.
Для урезания лога открываем Management Studio, выбираем нужную базу, нажимаем на ней правой клавишей мыши и в открывшемся контекстном меню выбираем пункт «Properties». Переходим на вкладку «Options» и изменяем модель восстановления базы (Recovery model) на Simple.
После завершения операции возвращаем режим восстановления базы обратно в Full.
Тоже самое можно проделать из Query Analizer с помощью скрипта:
USE ″Имя базы″
ALTER DATABASE ″Имя базы″ SET RECOVERY SIMPLE
DBCC SHRINKFILE (″Имя файла лога″, ″Желаемый размер″);
ALTER DATABASE ″Имя базы″ SET RECOVERY FULL
Одна из самых моих горячих проблем касается сжатия файлов данных. Несмотря на то, что я владел кодом сжатия, когда работал в Майкрософт, у меня не было шанса переписать его так, чтобы сделать его более приятным. Мне действительно не нравится сжатие.
Прошу, не путайте сжатие журнала транзакций со сжатием файлов данных. Сжатие журнала необходимо, если ваш журнал вырос сверх допустимых пределов, или при избавлении от избыточной фрагментации виртуальных файлов журнала (смотрите здесь (английский) и здесь (английский) замечательные статьи Кимберли). Тем не менее, сжатие журнала транзакций должно быть редкой операцией и никогда не должно входить ни в одну регулярную программу обслуживания, которую вы выполняете.
Сжатие файлов данных должно выполняться еще реже, если должно вообще. И вот почему — сжатие файлов данных вызывает серьезнейшую фрагментацию индексов. Позвольте мне продемонстрировать это на простом скрипте, который вы можете выполнить сами. Скрипт ниже создаст файл данных, создаст таблицу-«наполнитель» размером 10Мб в начале файла данных, создаст «производственный» кластерный индекс размером 10Мб, и потом проанализирует фрагментацию нового кластерного индекса.
Логическая фрагментация кластерного индекса перед сжатием равна близким к идеальным 0.4%.
Теперь я удалю таблицу-наполнитель, запущу сжатие, чтобы освободить место и снова проверю фрагментацию кластерного индекса:
Ого! После сжатия логическая фрагментация почти 100%. Операция сжатия полностью фрагментировала индекс, лишая любого шанса на эффективное сканирование диапазонов в этом индексе путем обеспечения ситуации, когда все упреждающие операции ввода-вывода со сканированием диапазона будут одностраничными операциями ввода-вывода.
Почему такое произошло? Операция сжатия файла данных работает с одним файлом за раз, и использует глобальную карта распределения (GAM) (смотрите статью «Внутри Storage Engine: GAM, SGAM, PFS и другие карты распределения», английский) чтобы найти самую последнюю страницу, размещенную в файле. Затем она перемещает эту страницу настолько близко к началу файла, насколько это возможно, и снова, и снова повторяет такую операцию. В ситуации выше, это полностью развернуло порядок кластерного индекса, сделав его из полностью дефрагментированного полностью фрагментированным.
Одинаковый код используется в командах DBCC SHRINKFILE, DBCC SHRINKDATABASE, и при автосжатии – они одинаково плохи. И вместе с фрагментацией индекса, сжатие файлов данных генерирует большое количество операций ввода/вывода, активно использует процессорное время и генерирует большое количество записей в журнале транзакций — поскольку все, что оно делает, полностью журналируется.
Сжатие файлов данных никогда не должно быть частью регулярного обслуживания, и вы НИКОГДА, НИКОГДА не должны включать автосжатие. Я пытался добиться его исключения из SQL Server 2005 и SQL Server 2008, когда я был в должности, позволяющей добиваться этого – единственная причина, почему оно еще есть — это обеспечение обратной совместимости. Не попадайтесь в ловушку создания плана обслуживания, который перестраивает все индексы и потом пытается освободить место, занятое при перестроении индексов, запуском сжатия — это игра с нулевой суммой, где все, что вы делаете — это генерируете записи в журнале транзакций с нулевой реальной пользой для производительности.
Так когда вам может быть нужно запустить сжатие? Например, если вы удалили большую часть очень большой базы данных и база данных вряд ли вы вырастет или если вам необходимо очистить файл перед его удалением?
Я рекомендую следующий метод:
- Создайте новую файловую группу
- Переместите все вовлеченные таблицы и индексы в новую файловую группу, используя синтаксис CREATE INDEX … WITH (DROP_EXISTING = ON) ON, чтобы переместить таблицы и убрать фрагментацию из них одновременно
- Удалите старую файловую группу, которую вы все равно собирались сжимать (или сожмите ее по максимуму, если это первичная файловая группа)
На самом деле вам необходимо обеспечить дополнительное свободное пространство, прежде чем вы сможете сжать старые файлы, но это гораздо более чистый механизм.
Если у вас нет совершенно никакого выбора и вы должны запустить операцию сжатия файлов, будьте готовы к тому, что вы вызовете фрагментацию индексов и вы должны предпринять действия, чтобы убрать ее впоследствии если она вызовет проблемы с производительностью. Единственный способ убрать фрагментацию индекса без роста файла данных — это использование DBCC INDEXDEFRAG или ALTER INDEX … REORGANIZE. Эти команды требуют дополнительно одной страницы размером 8Кб, вместо необходимости построения полностью нового индекса в случае выполнения операции перестроения.
Итог – пытайтесь избегать запуска сжатия файлов любой ценой!