
Автор: Zheka. Дата публикации: 17 июля 2019 . Категория: Офис. Просмотров: 4901

Электронные книги вошли в нашу повседневную жизнь и продолжают укреплять свою позицию. PDF – один из самых популярных форматов, который можно встретить на интернет просторах, посещая сайты и магазины. Но бывают досадные ситуации, когда текст, который мы хотим скопировать, просто превращается в непонятные символы. Кто-то на них говорит иероглифы, другие – кракозябры . Как же исправить такую ситуацию?
Я не уверен, что следующие советы помогут для всех решить проблему, но частичное решение ее все же возможно.
Давайте сразу отбросим отсканированые и нераспознанные PDF документы, из которых просто невозможно скопировать текст. Это равносильно попытке копирования текста из обычной фотографии, сделанной на ваш смартфон. В таком случае текст нужно распознать специальной программой, вроде ABBYY FineReader.
Наша книга (тестовая) полностью поддерживает копирование текста и изображений. Но при попытке перенести такой текст в Microsoft Office Word, можно видеть такие нечитабельные символы как на скриншоте сверху статьи.
Способ 1 (длинный).
Вся проблема в шрифтах и системе кодирования. PDF документ, с которого производится копирование имеет встроенные шрифты. И если такие шрифты отсутствуют в вашей операционной системе, то вы увидите такие кракозябры .
Чтобы можно было видеть нормальные буквы, при переносе текста нужно устанавливать соответствующие шрифты .
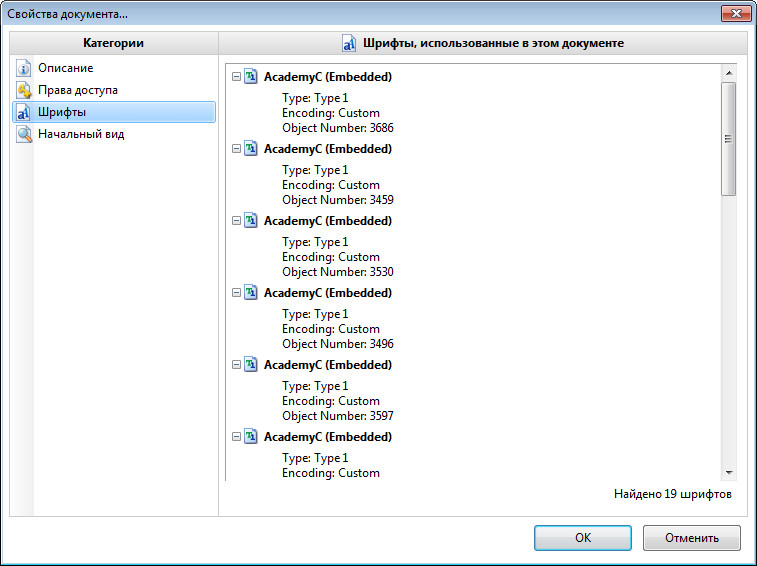
Чтобы узнать какие именно нужно инсталлировать на компьютер шрифты, нужно открыть наш PDF документ поддерживаемой программой (на примере PDF-XChange Viewer ). Далее идем в «Файл» → «Свойства документа» (можно нажать сочетание клавиш Ctrl + D).

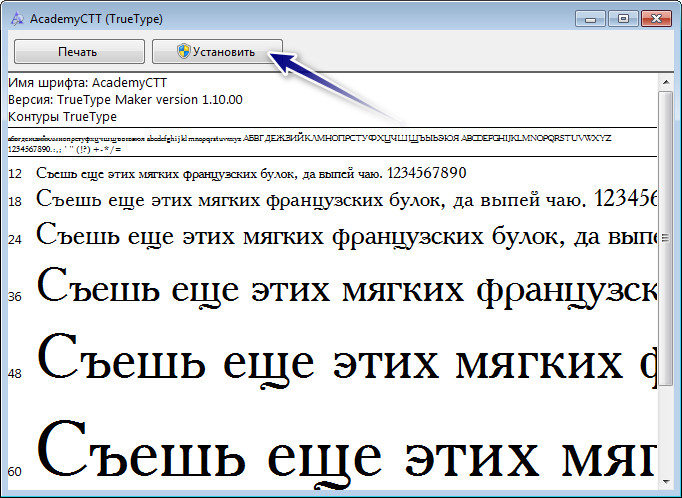
Далее нажимаем на параметр «Шрифты» и видим список шрифтов, установленных в документе. Их и нужно найти в интернете и установить на компьютер. Для этого на загруженном шрифте два раза нажимаем левой клавишей мыши (то есть, открываем его), а потом нажимаем на кнопку «Установить» .
Далее копируем и вставляем текст из PDF документа, выделяем его в Microsoft Office Word (или в другом офисном редакторе, который у вас установлен) и выбираем из списка недавно установленный шрифт. Все должно быть нормально. Снизу на скриншоте видно, что я намеренно применил нужный шрифт только на одно предложение, другую часть текста прочитать невозможно.

Способ 2 (быстро и удобно).
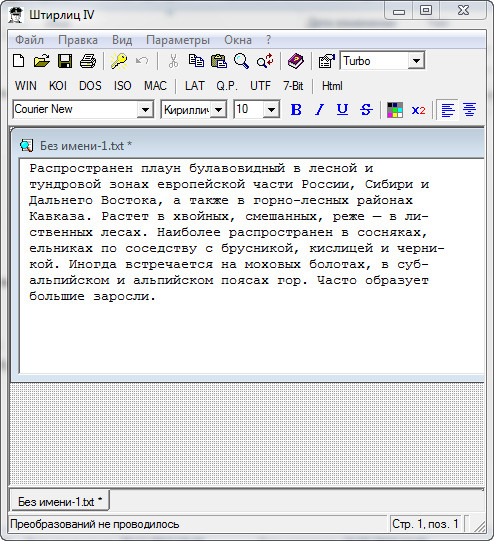
Другой, более правильный и простой вариант – это использование программы (или плагина к редактору Notepad ++ ), которая называется Shtirlitz. Программа старая, давно не обновлялась, однако работает отлично. Прямо на лету выполняется вставка нормального текста. Никаких шрифтов не требуется. После копирования текста с данной программы и дальнейшей вставкой его в редактор Microsoft Office Word, все буквы и символы будут читаться и с использованием любого шрифта. Первый вариант не позволяет изменить шрифт. То есть, всегда, и на каждом компьютере нужно будет инсталлировать нужные шрифты для чтения только определенного документа. А если таких документов несколько сотен? Поэтому желательно воспользоваться этой программой для декодирования.
Способ 3 (онлайн).
Кто не хочет использовать программу Shtirlitz или она не работает, может использовать следующие онлайн сервисы для перекодирования (отдельные сервисы имеют ограничения по объему текста).
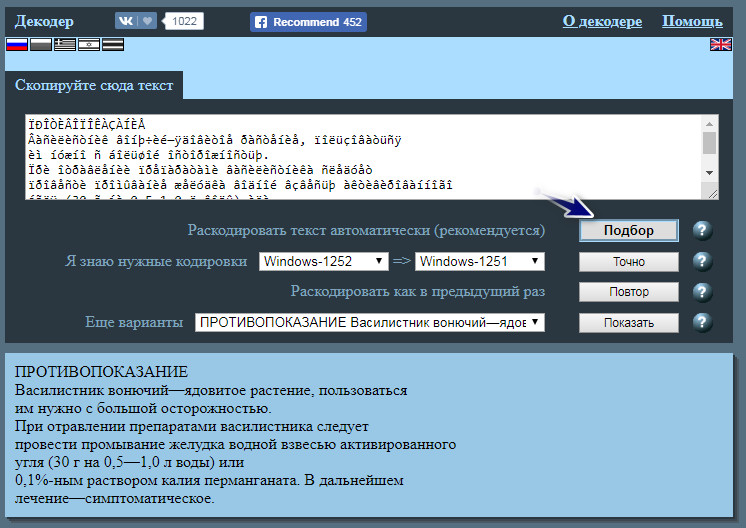
Обратите внимание, что кодирование нашей тестовой книги windows-1252. Для нас нужна кодировка windows-1251. Поэтому переходим на сервис online-decoder.com.
Там можно видеть окно, где написано «Скопируйте сюда текст». Вставляем наш непонятный текст и нажимаем на кнопку «Подбор». Такой способ будет правильно использовать если вам неизвестна система кодирования. Декодер попытается подобрать ее автоматически. Если вы знаете исходное кодирование своей кракозябры, то можете смело нажимать кнопку «Точно», указав перед этим кодирование, напротив текста «Я знаю нужные кодировки».
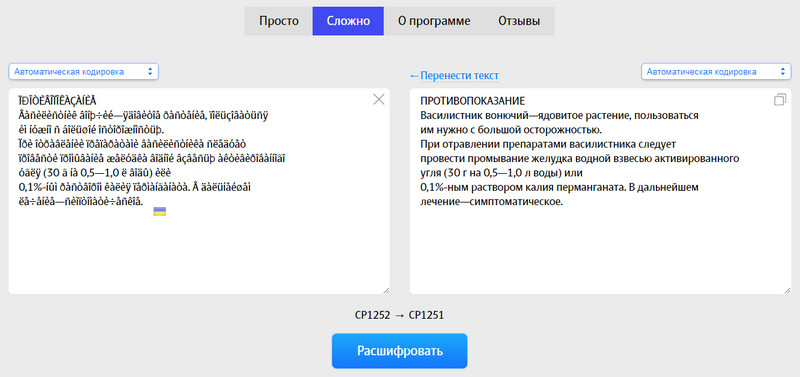
Второй сервис «artlebedev.ru». Есть два способа для декодирования: «Просто» и «Сложно». Первый вариант работает на автомате. Второй – дает возможность, при необходимости, указать исходное и конечное кодирование.
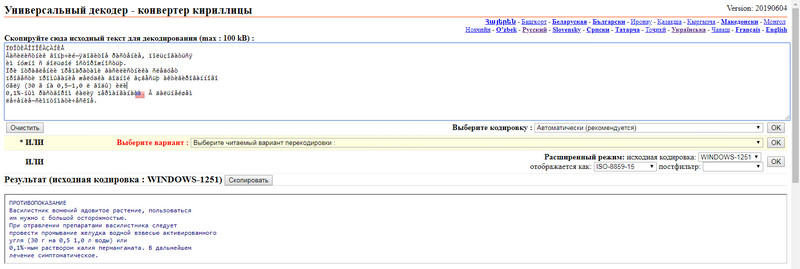
Третий онлайн сервис для декодирования текста «2cyr.com» имеет отличие от предыдущих в том, что позволяет выбирать язык. Кроме русского, доступен также и украинский язык интерфейса (и надеюсь, что кодирования также, просто не было возможности проверить).
Есть также два режима: автоматический и режим эксперта. Во втором можно указывать исходное и конечное кодирование. Рекомендуется автоматический режим. После того как вставили текст, напротив слов «Выберите кодировку : » , нужно выбрать «Автоматически (рекомендуется)» и нажать на кнопку «Ок».
Все три сервиса отлично работали на моей тестовой книге в формате PDF с кракозябрами.
Способ 4 (с помощью макросов для Microsoft Office Word ).
Еще один вариант для программы Microsoft Office Word. Никаких шрифтов ставить не нужно. Создаем макрос со следующим кодом:
Код 1: «Перекодирование 1252 в 1251»
Sub Corr1252_1251()
Dim s$, i&, j&
s = Selection
For i = 1 To Len(s)
j = AscW(Mid$(s, i, 1))
If j ‘ Debug.Print i & vbTab & Mid$(s, i, 1) & vbTab & j & vbTab & Chr(j)
End If
Next
Selection.Text = s
End Sub
Код 2: «Перекодирование 1252 в 1251 (с учетом русской буквы Ё)»
Sub changeToRus()
‘
‘ Замена кракозябр на кириллические буквы
‘ CP1252 -> CP1251
‘
For i = 192 To 255
a1 = i
a = Trim("^u") & Trim(Str(a1))
‘ Формирование запроса для поля Найти
sRus = Array("А", "Б", "В", "Г", "Д", "Е", "Ж", "З", "И", "Й", "К", "Л", "М", "Н", "О", _
"П", "Р", "С", "Т", "У", "Ф", "Х", "Ц", "Ч", "Ш", "Щ", "Ъ", "Ы", "Ь", "Э", "Ю", "Я", _
"а", "б", "в", "г", "д", "е", "ж", "з", "и", "й", "к", "л", "м", "н", "о", _
"п", "р", "с", "т", "у", "ф", "х", "ц", "ч", "ш", "щ", "ъ", "ы", "ь", "э", "ю", "я")
‘ Формирование массива кириллических букв для поля Заменить
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = a
.Replacement.Text = sRus(i — 192)
.Forward = True
.Wrap = wdFindContinue
.MatchCase = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
‘ Выполнение замены по тексту
Next i
‘ Замена Ё и ё
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(168)
.Replacement.Text = "Ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = ChrW(184)
.Replacement.Text = "ё"
.Forward = True
.Wrap = wdFindContinue
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Выделяем вставленный текст с иероглифами. Тогда запускаем макрос на выполнение и получаем нормальный текст, который можно спокойно редактировать, изменять шрифты и т.д.
Для добавления готового макроса в Word делаем следующее:
Открываем редактор и переходим в «Вид».

Там находим кнопку «Макросы» и нажимаем на нее.
Даем для макроса имя (любое, оно будет автоматически изменено при полном копировании кода выше).
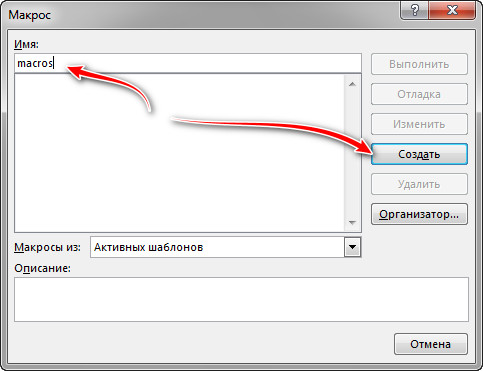
Откроется окно в котором можно заметить название нашего макроса. При желании можете оставить свое имя. Но лучше, чтобы не было ошибок, полностью заменить весь код на готовый (код смотрите сверху).
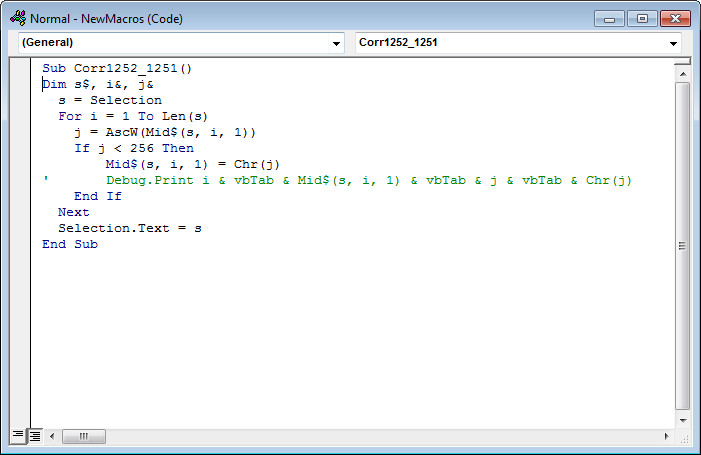
Как видно, макрос начинается так:
Sub названиемакроса()
дальше идет код макроса
End Sub
Название макроса может любым, но не цифры и не должно быть пробелов. Может быть так: декодирование_кракозябр_с_ё. Но не может быть так: декодирование кракозябр с ё.
То есть, для нас нужно заменить для нашего созданного пустого макроса весь текст с кодом, который показан выше.
После того как заменили, нужно закрыть окно редактирования макросов (можно нажать на иконку сохранения, хотя изменения сохраняются автоматически). Далее выделяем наш иероглифический текст, открываем макросы, выбираем из списка (если их у вас несколько) нужный и нажимаем на кнопку «Выполнить».

Ваш текст должен стать читабельным.

Источник макросов для Microsoft Office Word: http://wordexpert.ru
Как ни крути, но это не полное решение ситуации. Поиск после данных действий в самом PDF документе работать не будет. Проблема остается. Кто может подсказать ее решение, просьба писать в комментариях.
Т.к. вы неавторизованы на сайте. Войти.
Т.к. тема является архивной.
Копирую и получаю это: ɋɈȾȿɊɀȺɇɂȿ:
По гуглил. Много чего пишут, но решения не нашёл. У вас было такое? Какое то pdf’ник неправильный.

Первую Вашу реплику я прочёл как "он копирует в блокнот, где нет управления шрифтами".
Если вы имеете в виду что-то другое, то пожалуйста более однозначно выражайте свою мысль. ¶
классная штука!
1. попробовал пдф — ворд
Самый близкий результат к оригиналу выдал!
Получил это "CO?EPKAHEE:" вместо "содержание". Читать увы оч сложно такой текст.
2. Снял защиту. Копирую из пдф и вставляю в ворд. Получаю ерунду.
3. пдф со снятой защитой перевожу в ворд. Получаю "CO?EPKAHEE:"
Не пробиваемый ПДФ. ¶
я могу отдельные буквы и слова копировать в буфер.
Возможности проверить как на печати нет ( ¶
Английский текст из этого пдф копируется без ошибок! Причины точно в кодировке! Но как проблему решить, что это за кодировка? ¶
иногда помогает при вставке указать, что стандартная вставка без форматов . сам т текст в пдф отображается по русски же .
P.S. если тексты не секретные — киньте файл сюда — посмотрим )) ¶
где указать это?
нельзя файл выкладывать. ¶







Этот список в Акробат Ридере есть. Чем FoxitReader лучше? ¶
Ничем не лучше, просто именно это я и хотел увидеть изначально. Ваша проблема в том, что текст набран встроенным шрифтом в т.н. кастомной кодировке (CID, Identity-H). В системе его нет, поэтому при копировании нужно знать т.н. таблицу замещения для встроенного шрифта. Причина того, что копирование не работает в том, что этой таблицы замещения в документе нет:
This is relatively common, and is caused when the application creating the PDF fails to correctly embed the Unicode lookup table for the font. Without that lookup table there is no relationship between the visible character on screen and the equivalent character code, so copying and pasting the text will lead to either a series of unknown markers, or a jumble of characters with a 1:1 relationship to the original text.
As a PDF stores the character codes rather than the human-readable text, the fact you can see a letter "A" on the page doesn’t mean Acrobat has any idea that it’s an "A". The lookup tables make that connection, so if they’re missing or corrupted there’s no way to recreate the semantic connection unless you can re-fry the file with an original copy of the font.
forums.adobe.com/thread/758316
Поэтому вариант решения вашей проблемы такой:
— самостоятельно создать таблицу соответствий каждой буквы русского алфавита встроенного шрифта вашего документа соотв. юникод-символу
— далее написать скрипт, который будет делать подстановку, скопипасть исходный тескт в файл и обработать это скриптом. VBA из пакета Ms Office это прекрасно может сделать.
ЗЫ. Либо связаться с автором исходного документа и попросить его внедрить нормальный шрифт. ¶
Если установить шрифт с кастомной кодировкой (CID, Identity-H) в ОС, то будет всё работать? Осталось найти этот шрифт.
Зачем такие шрифты используют? ( ¶
Если вы установите именно тот самый кастомный шрифт, то должно сработать. Полагаю, что он может быть только у автора.
Последние комментарии
При вставке в Вордовский документ скопированного из сети текста с несколькими рисунками — в документе на месте необходимых рисунков — повторяются изображения самого первого рисунка, находящегося в копируемом блоке. Т.е. вместо 2 — N-го рисунков, — рисунок 1.
Как это исправить?
Понравилась статья? Подпишитесь на канал, чтобы быть в курсе самых интересных материалов