
Содержание
В прошлом году мы представили ML.NET, кросс-платформенную и открытую систему машинного обучения для разработчиков .NET. За это время она очень сильно развилась и прошла через множество версий. Сегодня делимся руководством по тому, как создать свое первое приложение на ml.net за 10 минут.

**Ниже туториал для Windows. Но ровно то же самое можно сделать и на MacOS/Linux.
Установите .NET SDK
Чтобы начать создавать приложения .NET, вам просто нужно скачать и установить .NET SDK (Software Development Kit).

Создайте свое приложение
Откройте командную строку и выполните следующие команды:
Команда dotnet создаст для вас new приложение типа console . Параметр -o создает директорий с именем myApp , в котором хранится ваше приложение, и заполнит его необходимыми файлами. Команда cd myApp вернет вас в созданный директорий приложения.
Установите пакет ML.NET
Чтобы использовать ML.NET, вам необходимо установить пакет Microsoft.ML. В командной строке выполните следующую команду:
Скачайте БД
Наше показательное приложение машинного обучения будет предсказывать тип цветка ириса (setosa, versicolor или virginica) на основе четырех характеристик: длина лепестка, ширина лепестка, длина чашелистика и ширина чашелистика.
Откройте репозиторий машинного обучения UCI: набор данных Iris, скопируйте и вставьте данные в текстовый редактор (например, «Блокнот») и сохраните их как iris-data.txt в каталоге myApp .
Когда вы добавите данные, это будет выглядеть следующим образом: каждый ряд представляет различный образец цветка ириса. Слева направо столбцы представляют: длину чашелистика, ширину чашелистика, длину лепестка, ширину лепестка и тип цветка ириса.
Используете Visual Studio?
Если вы используете Visual Studio, вам необходимо настроить iris-data.txt для копирования в output-директорий.
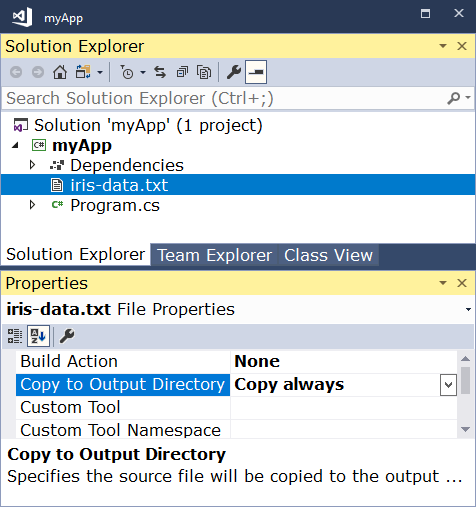
Немного покодим
Откройте Program.cs в любом текстовом редакторе и замените весь код следующим:
Запустите ваше приложение
В командной строке выполните следующую команду:
Последняя строка вывода — это предсказанный тип цветка ириса. Вы можете изменить значения, передаваемые в функцию Predict , чтобы увидеть прогнозы, основанные на различных измерениях.
ML.NET is a cross-platform open-source machine learning framework that makes machine learning accessible to .NET developers.
In this GitHub repo, we provide samples which will help you get started with ML.NET and how to infuse ML into existing and new .NET apps.
Note: Please open issues related to ML.NET framework in the Machine Learning repository. Please create the issue in this repo only if you face issues with the samples in this repository.
There are two types of samples/apps in the repo:
Getting Started  : ML.NET code focused samples for each ML task or area, usually implemented as simple console apps.
: ML.NET code focused samples for each ML task or area, usually implemented as simple console apps.
End-End apps  : End-user sample web and desktop apps infused with Machine Learning models based on ML.NET.
: End-user sample web and desktop apps infused with Machine Learning models based on ML.NET.
The official ML.NET samples are divided in multiple categories depending on the scenario and machine learning problem/task, accessible through the following tables:
 Sentiment Analysis C# F# |
 Spam Detection C# F# |
 Credit Card Fraud Detection (Binary Classification) C# F# |
 Heart Disease Prediction C# |
||
 Issues Classification C# F# |
 Iris Flowers Classification C# F# |
 MNIST C# |
 Product Recommendation C# |
 Movie Recommender (Matrix Factorization) C# |
Movie Recommender (Field Aware Factorization Machines) C# |
 Price Prediction C# F# |
 Sales Forecasting (Regression) C# |

Demand Prediction
C# F#
Sales Forecasting (Time Series)
C#

Sales Spike Detection C# C#
Power Anomaly Detection
C#
Credit Card Fraud Detection
(Anomaly Detection)
C#

Customer Segmentation
C# F#

IRIS Flowers Clustering
C# F#

Rank Search Engine Results
C#

Image Classification Training
(High-Level API)
C# Image Classification Predictions
(Pretrained TensorFlow model scoring)
C# F# C# Image Classification Training
(TensorFlow Featurizer Estimator)
C# F# 
Object Detection
(ONNX model scoring)
C# C#  Scalable Model on WebAPI C# |
Scalable Model on Razor web app C# |
 Scalable Model on Azure Functions C# |
 Scalable Model on Blazor web app C# |
 Large Datasets C# |
 Loading data with DatabaseLoader C# |
Loading data with LoadFromEnumerable C# |
 Model Explainability C# |
Automate ML.NET models generation (Preview state)
The previous samples show you how to use the ML.NET API 1.0 (GA since May 2019).
However, we’re also working on simplifying ML.NET usage with additional technologies that automate the creation of the model for you so you don’t need to write the code by yourself to train a model, you simply need to provide your datasets. The «best» model and the code for running it will be generated for you.
These additional technologies for automating model generation are in PREVIEW state and currently only support Binary-Classification, Multiclass Classification and Regression. In upcoming versions we’ll be supporting additional ML Tasks such as Recommendations, Anomaly Detection, Clustering, etc..
CLI samples: (Preview state)
The ML.NET CLI (command-line interface) is a tool you can run on any command-prompt (Windows, Mac or Linux) for generating good quality ML.NET models based on training datasets you provide. In addition, it also generates sample C# code to run/score that model plus the C# code that was used to create/train it so you can research what algorithm and settings it is using.
| CLI (Command Line Interface) samples |
|---|
| Binary Classification sample |
| MultiClass Classification sample |
| Regression sample |
AutoML API samples: (Preview state)
ML.NET AutoML API is basically a set of libraries packaged as a NuGet package you can use from your .NET code. AutoML eliminates the task of selecting different algorithms, hyperparameters. AutoML will intelligently generate many combinations of algorithms and hyperparameters and will find high quality models for you.
| AutoML API samples |
|---|
| Binary Classification sample |
| MultiClass Classification sample |
| Regression sample |
| Advanced experiment sample |
Additional ML.NET Community Samples
In addition to the ML.NET samples provided by Microsoft, we’re also highlighting samples created by the community showcased in this separated page: ML.NET Community Samples
Those Community Samples are not maintained by Microsoft but by their owners. If you have created any cool ML.NET sample, please, add its info into this REQUEST issue and we’ll publish its information in the mentioned page, eventually.
Translations of Samples:
See ML.NET Guide for detailed information on tutorials, ML basics, etc.
Check out the ML.NET API Reference to see the breadth of APIs available.
We welcome contributions! Please review our contribution guide.
Please join our community on Gitter 
This project has adopted the code of conduct defined by the Contributor Covenant to clarify expected behavior in our community. For more information, see the .NET Foundation Code of Conduct.

Код к этой статье можно скачать здесь.
В прошлом месяце, в их построения, корпорация Microsoft поделилась с нами планами .Чистая сердечник 3. Wile акцент был преобразование настольных приложений и поддержка Windows Forms и WPF, ML.NET -была также внедрена система машинного обучения. Если вы посмотрите на картину, которая была вокруг интернета в последнее время мы можем ожидать, что этот модуль является неотъемлемой частью .NET Core 3. Пока, ML.NET только в зачаточном состоянии, и мы можем попробовать его первое воплощение. Всего несколько дней назад 0.2 версия ML.NET было объявлено, так что давайте посмотрим, что это за рамки.
ML.NET является с открытым исходным кодом и кросс-платформенной платформой и доступен в виде пакета NuGet. Вы можете проверить код здесь. Он был первоначально разработан в Microsoft Research и используется во многих продуктах Microsoft, таких как Windows, Bing, Azure и т.д. Одна очень классная вещь в этой структуре заключается в том, что ее можно расширить, чтобы добавить библиотеки машинного обучения, такие как TensorFlow, Accord.NET и CNTK. Прежде чем мы углубимся в детали этой структуры давайте краткое Введение в машинное обучение и тип проблем, которые он решает.

Машинное обучение-это отрасль информатики, которая использует статистические методы, чтобы дать компьютерам возможность научиться решать определенные проблемы без явного программирования. Несмотря на то, что это большой модное слово в эти дни и “жизнь партии” на каждой конференции, первоначальные концепции машинного обучения уходят в 50-е годы. Вся идея заключается в том, чтобы разработать определенную модель, которая после того, как будет обучена некоторому набору данных, сможет сделать правильные прогнозы, используя новые данные.
Проще говоря, модель использует исторические данные для прогнозирования новых данных, и весь этот процесс называется прогнозным моделированием. Или математически сказал, мы пытаемся примерное отображение функция – Ф от входных переменных х до выходных переменных у. В машинном обучении, мы используем предиктивного моделирования для решения двух типов задач: регрессии и классификации.
Задачи регрессии требуют прогнозирования количества. Наши Выходные данные непрерывны, что означает, что это реальное значение, такое как целое или значение с плавающей точкой. Например, мы хотим прогнозировать нашу зарплату на основе данных за последние пару месяцев. Проблемы классификации, с другой стороны, пытаются разделить вклад на определенные категории. Это означает, что Выходные данные этих задач дискретны. Например, мы пытаемся предсказать, является спам по электронной почте или нет.
Есть несколько подходов, когда это можно взять при обучении модели: контролируемое обучение, неконтролируемое обучение и усиленное обучение. При обучении под наблюдением модели предоставляются входные данные и ожидаемые результаты, а модель изучает, какие Выходные данные должны быть предоставлены для определенного типа входных данных. Этот тип обучения является наиболее популярным.
Проблема Классификации Цветков Ириса

Ок, теперь, когда мы находимся в курс основные понятия машинного обучения, давайте посмотрим, какую проблему мы собираемся решить с помощью ML.NET. Ирис набор данных известен набор данных в мире для распознавания и считается “Привет мировой” пример для машинного обучения классификации проблем. Он впервые ввел Рональд Фишер, британский статистик и ботаник, еще в 1936 году. В своей статье Тон использует несколько измерений в таксономических проблем, он использовал данные, полученные для трех различных классов растений Ирис: Ирис setosa, Ирис virginica, и Ирис лишай.
Этот набор данных содержит 50 экземпляров для каждого класса. Что интересно во всем этом примере, так это то, что первый класс линейно отделим от двух других, но последние два не линейно отделимы друг от друга. Каждый экземпляр имеет пять атрибутов
- Sepal Длина в см
- Ширина Sepal в см
- Длина лепестка в см
- Ширина лепестка в см
- Класс (setosa Айрис, Айрис virginica,Ирис лишай)
Если вы заинтересованы в том, как эта проблема может быть решена с помощью нейронных сетей, вы можете проверить эту реализацию через Tensorflow, или это один через водоснабжении.

На данный момент ML.NET работает .Чистая ядра 2.0, поэтому убедитесь, что вы установили на вашем компьютере. Обратите внимание, что в настоящее время он должен выполняться в 64-разрядном процессе. Помните об этом при создании консольного приложения. Как и любой другой пакет NuGet, его можно установить с помощью консоли диспетчера пакетов с помощью команды
Другой способ сделать это-использовать CLI .NET Core. Если вы собираетесь использовать этот подход, убедитесь, что вы установили .Чистый базовый пакет SDK. Затем выполните эту команду из папки проекта консольного приложения
Также можно использовать графический интерфейс Visual Studio. Все, что вам нужно сделать, это щелкните правой кнопкой мыши проект и выберите Управление пакетов nuget вариант

После этого, вам нужно найти Майкрософт.Мл пакет и установить его.

Наконец, давайте перейдем к веселому материалу и реализуем решение проблемы классификации радужной оболочки глаза. Вы можете найти код для этой реализации здесь. Первое, что нам нужно сделать, это получить данные. Мы можем найти полный набор данных, с 150 образцов здесь.
Однако обычной практикой при построении модели является наличие набора данных для обучения и другого набора данных для тестирования и оценки точности модели. Часто, как и в этом примере, мы получаем только один набор данных, который нам нужно разбить на два отдельных набора данных и который используется один для обучения, а другой для тестирования. Соотношение должно быть около 80% до 20%. Именно поэтому я выбрал 25 образцов из набора данных и сохранил их в отдельных файлах.

Вот как выглядит один из этих файлов

Построение и обучение модели
Данные, отраженные в этом .csv-файлы должны быть преобразованы в какие-то объекты. Именно поэтому в нашем Ирис папку, мы имеем два класса: IrisFlower и IrisPredict. Информация из файлов наших наборов данных окажется в этих объектах, а затем мы сможем использовать их для обучения нашей модели и создания прогнозов. Мы увидим, как эти классы используются в минуту, на данный момент, посмотрите, как они реализуются
| используя Майкрософт.Мл.Во время выполнения.API-интерфейс; |
| пространство имен IrisClassification.Ирис |
| < |
| общественный класс IrisFlower |
| < |
| [Столбец(«0»)] |
| публичных поплавок SepalLength; |
| [Столбец(«1»)] |
| публичных поплавок SepalWidth; |
| [Столбец(«2»)] |
| публичных поплавок PetalLength; |
| [Столбец(«3»)] |
| публичных поплавок PetalWidth; |
| [Столбец(«4»)] |
| [Имя_столбца(«Метка»)] |
| публичных строку ярлыка; |
| > |
| общественный класс IrisPredict |
| < |
| [Имя_столбца(«PredictedLabel»)] |
| общественного строка PredictedLabels; |
| > |
| > |
Теперь, давайте проверим основной способ нашего решения. Вы можете видеть, что многие вещи расположены в других классах, но здесь мы можем увидеть полный рабочий процесс. В modelbuilder подается с подготовки данных для учебного процесса и тестовых данных для оценки процесса. После чего результаты отображаются в консоли с помощью IrisCsvReader.
| используя IrisClassification.Помощники; |
| с помощью системы; |
| используя Майкрософт.Мл.Данные; |
| пространство имен IrisClassification |
| < |
| класс программа |
| < |
| статический пустота главный(строка[] аргументы) |
| < |
| вар trainingDataLocation = @»сведения/Айрис-data_training.кшм»; |
| вар testDataLocation = @»сведения/Айрис-data_test.кшм»; |
| // Построения и оценки модели. |
| вар в modelbuilder = новое окно modelbuilder(trainingDataLocation); |
| вар модель = в modelbuilder.Построить(); |
| вар точность = в modelbuilder.Оценки(модель, testDataLocation); |
| Консоль.Метода writeline($»*************************************************»); |
| Консоль.Метода writeline($»* точность модели : <точность>*"); |
| Консоль.Метода writeline($"*************************************************"); |
| // Визуализации результатов. |
| вар testDataObjects = новый IrisCsvReader().GetIrisDataFromCsv(testDataLocation); |
| по каждому элементу (вар ирис в testDataObjects) |
| < |
| вар предсказание = модель.Прогнозирования(ирис); |
| Консоль.Метода writeline($"————————————————-"); |
| Консоль.Метода writeline($"предсказал Тип : <предсказание.PredictedLabels>"); |
| Консоль.Метода writeline($"фактический Тип : <Айрис.Метка>"); |
| Консоль.Метода writeline($"————————————————-"); |
| > |
| Консоль.С readline(); |
| > |
| > |
| > |
Мы видим, что по сути все самое интересное происходит в окне modelbuilder класс. Вы можете найти весь класс здесь. В двух словах, этот класс имеет два метода BuildAndTrain и оценить. Первый способ, BuildAndTrain, используется для создания модели и подготовки ее. Вот как это выглядит
| /// |
| /// С помощью обучающих данных местоположения, который передается через конструктор этот метод строит |
| /// и обучение машинного обучения модели. |
| /// |
| /// обучение машинного обучения модели. |
| общественные PredictionModel BuildAndTrain() |
| < |
| вар трубопровода = новый LearningPipeline(); |
| трубопровода.Добавить(новый TextLoader(_trainingDataLocation).CreateFrom (useHeader: правда, разделитель: ‘,’)); |
| трубопровода.Добавить(новый Dictionarizer("метка")); |
| трубопровода.Добавить(новый ColumnConcatenator("функции", "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")); |
| трубопровода.Добавить(новый StochasticDualCoordinateAscentClassifier()); |
| трубопровода.Добавить(новый PredictedLabelColumnOriginalValueconverter() < PredictedLabelColumn = "PredictedLabel" >); |
| возврат трубопровод.Поезд |
| > |
Для создания модели, мы используем LearningPipeline. Этот класс используется для определения задач, которые наши модели должен делать. Он инкапсулирует загрузку данных, обработку данных/featurization и алгоритм обучения. Все эти шаги Добавлено через Добавить способ из этого класса.
Обучение данные о местоположении передается через конструктор в modelbuilder, и используется в первый шаг – загрузка данных. Здесь мы используем TextLoader класс и уже реализованных IrisFlower класс. В этой линии, мы говорим, что как только тренировка началась, мы должны загрузить данные из обучающих данных местоположения и сопоставить его с IrisFlower объектов. После этого, мы добавляем Dictionizer в трубопровод. Чтобы понять, что этот шаг сделает, мы должны снова взглянуть на наши данные.
Обратите внимание, что последний столбец в данных представляет специи цветка ириса в строковом формате. Алгоритмы машинного обучения не могут работать со строками. Также обратите внимание, что этот столбец отображается на этикетке собственность IrisFlower. Под капотом, это Dictionizer класс кодировать текст в некоторое количество, поэтому наш алгоритм машинного обучения, умеет использовать его. Наконец, мы добавляем ColumnConcatanator собрать все атрибуты. С этим, мы закончили с подготовкой данных для нашего процесса обучения.
Три последних шагов в BuildAndTrain способа являются критическими. Мы добавляем тип модели, который мы собираемся использовать. Для этой цели мы используем Стохастическийдвойнойкоординатподъемклассификатором класс. Этот шаг построит нашу модель. Затем мы добавляем PredictedLabelColumnOriginalValueconverter класса, который используется для преобразования закодированных выходное значение обратно в строку. Наконец, мы называем железнодорожного метод, трубопровод выполнен и обучения модели.
Второй способ построения модели используется модель оценки. Вот код этого метода
| /// |
| /// Уссинг прошли тестирование данных и модели, расчет модели по точности. |
| /// |
| /// точность модели. |
| публичных двойной оценке(PredictionModel модель, строку testDataLocation) |
| < |
| Варе данных testdata = новый TextLoader(testDataLocation).CreateFrom (useHeader: правда, разделитель: ‘,’); |
| вар метрики = новый ClassificationEvaluator().Оценки(модель, ними); |
| возврат метрики.AccuracyMacro; |
| > |
Это гораздо проще, что BuildAndTrain способ. В основном, мы загружаем данные с помощью TextLoader класс снова, но на этот раз мы с помощью тестовых данных. После этого, мы используем ClassigicationEvaluator класса и оценивать способ на предоставленную модель и тестовых данных. Этот метод возвращает объект, который содержит метрическую информацию о модели – ClassificationMetrics объекта. Мы хотим видеть только точность, поэтому мы возвращаемся AccuracyMacro.
Визуализация выходных данных
Просто чтобы увидеть, как наша модель работает, мы добавили один класс, который читает от .CSV-файл и создает IrisFlowers объекты – IrisCsvReader класс. Это довольно просто
| общественный класс IrisCsvReader |
| < |
| публичный интерфейс ienumerable GetIrisDataFromCsv(строка dataLocation) |
| < |
| вернуть файл.ReadAllLines(dataLocation) |
| .Пропустить(1) |
| .Выберите(х => х.Сплит(‘,’)) |
| .Выберите(х => новый IrisFlower() |
| < |
| SepalLength = поплавок.Разбираем(х[0]), |
| SepalW > |
| PetalLength = поплавок.Разбираем(х[2]), |
| PetalW > |
| Метка = х[4] |
| >); |
| > |
| > |
Этот метод вызывается в основной способ нашего приложения. Для каждого объекта, который GetIrisDataFromCsv метод возвращает, мы называем прогнозирования метод модели, а мы потом распечатать прогнозируемое значение с фактическим значением. Так выглядит вывод нашего приложения

Точность модели 100%. Я бы забеспокоился о том, чтобы переусердствовать, если бы мы использовали какие-то другие данные и работали над более сложной проблемой. Тем не менее, мы работали с простыми данными, и этот результат несколько ожидается. Под этим вы можете видеть, что наша модель дает правильные прогнозы для каждого образца из тестовых данных.