
Содержание
Что такое Парсинг и что это означает ?
Парсинг это синтаксический анализ или разбор (англ. parsing) данных. По факту это означает разбор содержимого страницы на отдельные составляющие, в нашем случае html кода страниц(ы).
В этой статье мы будем автоматически вытаскивать нужную нам информации со страницы веб-сайта и сохранять в формате CSV.
CSV (от англ. Comma—Separated Values — значения, разделённые запятыми) — текстовый формат, предназначенный для представления табличных данных.
Задача номер ноль.
Что бы получить данные с сайта первым делом надо получить код (html) страницы этого сайта. Для решения этой задачи будем использовать библиотеку requests . requests это по сути обертка библиотеке urllib которая упрощает работу с запросами к веб-серверу и т.д. Что очень удобно, получить страницу занимает всего две строчки :
Мы отправляем GET запрос серверу requests.get(url) . И возвращаем данные которые содержаться в поле text .
Задача номер один.
Собственно теперь у нас есть данные что бы их парсить. В качестве самого парсера мы будем использовать библиотеку BeautifulSoup . Soup переводиться как суп , не поверите. Вот такое забавное название, будем варить суп ) Есть и другие библиотеки в том числе и входящие уже в Питон.
Теперь нам надо придумать откуда мы будем вытаскивать информацию и какую. Для примера возьмем сайт 3dnews.ru и будем собирать все заголовки статей с раздела Новости Hardwear .

Так как структура, верстка и т.д. всех сайтов разная нам надо еще понять где именно хранятся заголовки статей. Есть конечно мощные, универсальные парсеры но это не про нас. Я новичок и сатья рассчитана на таких же новичков. По этому идем в инструмент разработчика и ищем наши заголовки. Тут конечно требуется базовое знание языка html . Но я думаю даже если вы совсем не знакомы быстро разберетесь.

Давайте перейдем к коду парсера и я вам постараюсь все разъяснить:
Создаем сам объект , передаем в него наш код страницы (html) и ‘lxml’ , в качестве интерпретатора кода. LXML библиотека для обработки XML и HTML .
Теперь с помощью метода fine() найдем блок со статьями,
— это блочный элемент, внутри которого могут находиться другие теги, содержание веб страницы. Своего рода, это контейнер, который можно легко видоизменять и выводить в любом месте веб страницы с помощью CSS.
Кроме id есть еще class, но слово класс зарезервировано в питон по этому в библиотеке используется
Наш список все еще является объектом BeautifulSoup и мы можем к нему применять все методы библиотеки. Переберем весь список тегов и вытащим из него текс методов .string .
Возвращаем уже текстовый список с заголовками статей.

Но одни заголовки это мало , давайте еще вытащим ссылки на эти статьи. Смотрим внимательно на код страницы. По факу заголовки и есть ссылки , тег

Теперь мы в цикле вытаскиваем ссылки и заголовки, не забываете что мы может применять все методы библиотеки.
Создадим словарь и отправим его на запись в файл:
Задача номер три.
Теперь создадим функцию записи в файл в формате CSV.
Открываемсоздаем файл , ‘a’ — значит добавить данные в конец файла, если файла нет создать.
У веб-мастеров часто возникает ситуация, когда надо проанализировать чужой сайт или просто спарсить с него часть контента. Это может пригодиться для того, чтобы на основе полученного чужого контента делать дорвеи, отдавать текст на рерайт другим авторам или просто проводить первичный автоматический перевод с Google Translate.
Да и вообще: автоматический парсинг сайта или сайтов полезен в куче прикладных вещей, слабо связанных непосредственно с последующей контент-маркетингом. Например, достаточно часто техника применяется для парсинга страниц интернет-магазина, когда его лень наполнять самостоятельно; часто техника применяется для парсинга цен и уведомлении о наиболее приятной цены. Нередко парсинг сайтов (web dcraping) применяется просто для мониторинга новостей по определенной метке или тегу.
Впервые я столкнулся с Web Scraping как таковым достаточно давно, еще когда работал в web-студии. Тогда я пользовался Scrapinghub, однако, инструмент нельзя было назвать гибким. С появлением некоторого свободного времени и увлечении Python решено было сделать собственный инструмент. Однако, как показала праткика, сделать универсальный инструмент на все случаи жизни не получается: слишком разные сайты необходимо парсить, и к каждому нужен индивидуальный подход. В результате появился некоторый опыт, с которым и хотелось бы поделиться. Python-програмимсты Middle уровня и выше вряд ли найдут в этой статье что-то полезное, но новичкам, думаю, статья будет в масть.
Инструменты
Инспектор объектов Chrome
Как уже было сказано, уникальный скрипт создать весьма сложно. Данные хранятся в разных дивах разного уровня вложенности, и везде есть своя специфика. В 99% случаев перед непосредственно парсингом приходится вдумчиво изучать HTML-структуру исследуемых страниц, править код, и только потом натравливать скрипт на домен.
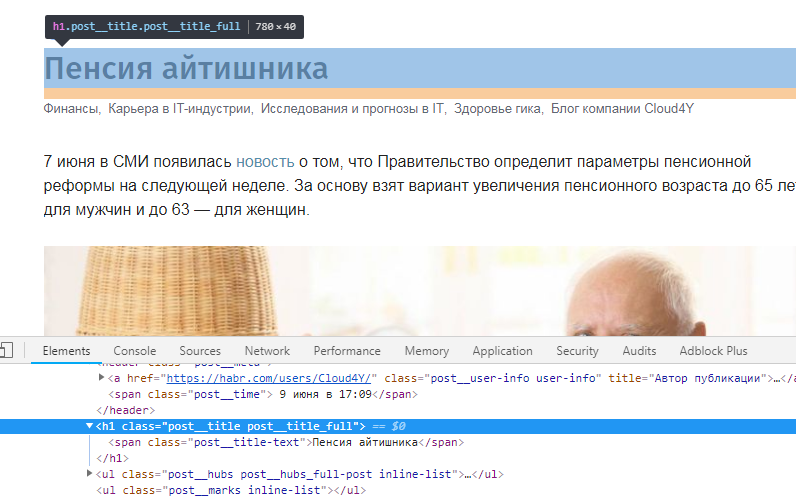
В подавляющем большинстве случаев для этого хватает встроенного в Chrome инспектора объектов. Например, хабр на странице поста хранит название статьи в строке post__title-text блока post__title post__title_full.
Scrapy
Есть готовый фреймворк для парсинга – Scrapy. Он удобен тем, что позволяет работать с куками (а, следовательно, обходит примитивные бот-детекторы), работать с задержкой, адекватно обрабатывает исключения. Однако вход к Scrapy достаточно высок, и лично я бросил этот фреймворк на полпути: мои прикладные задачи позволяют обходиться артиллерией меньшего калибра.
К тому же, для вебмастера, который пытается взять в займы чужой контент для своих доров, функционал Scrapy может показаться избыточным.
BeautifulSoup
BeautifulSoup – моя правая рука. Она позволяет достаточно легко обрабатывать HTML, полученный с помощью библиотеки requests. Своего рода, золотая середина между собственный велосипедом и Scrapy, середина, которой лично я и пользуюсь.
Работает с BeautifulSoup, вам нужно быть готовым ктому, что вам придется самостоятельно обрабатывать исключения, в том числе связанные с блокировкой IP, самостоятельно думать об анонимизации и проксях, самостоятельно же городить способ экспортирования данных.
Основной функционал
Основной функционал заключается в том, чтобы просто забрать текст из нужного нам блока. Для этого стоит разобраться, в каких div-ах блок находится. Допустим, у нас есть следующая структура документа:
Соответственно, чтобы достать «Нужный контент, который мы и сохраним», требуется сделать такое:
Соответственно, если блоков, удовлетворяющих условию селектора несколько, то нужно выбрать нужный индекс в массиве p3. Ну а потом уже решать, что вам нужно, а что нет.
Возможные проблемы
Названия классов и их ID
Методология следования названию классов помогает в 90% случаев. Некоторые сайты автоматически генерируют названия класса (привет, WineStyle!) именно для того, чтобы их не парсили. В этом случае иногда помогает привязываться к id блока, а не его class. А иногда – ен помогает.
Использованиt заголовков и user-agent
Некоторые серверы не пускают вас к себе, если у вас пустой заголовок запроса. Вэтом случае. А некоторые сайты просто показываются разный контент для разных user-agent-ов (хотя это люто наказывается поисковиками). Да и вообще – генерируя десятки (а то и сотни) запросов в секунду нужно быть готовым к бану. Для работы с этим лучше использовать библиотеку user-agent:
Таймаут
Библиотека requests будет ждать ответа от сервера бесконечно долго, поэтому, лучше ограничить ее в этом удовольствии, установив тайм-аут.
Коды ответа сервера
Рано или поздно вас забанят. Чтобы нормально обрабатывать это событие, нужно смотреть коды состояния ответа сервера. При бане часто отдаются коды 404, 408, 403, 500.
Можно использовать и другую конструкцию для обработки HTTP-исключений:
Вторая конструкция позволяет более детально проанализировать все ошибки и разобраться в их причине.
Смена IP адресов
Библиотека Requests приятна еще и тем, что по умолчанию поддерживает работу с прокси. Делается эо следующим образом:
В английском языке это явление называется Honeypots («горшочек c медом»), хотя термин «мина» мне нравится больше. Мина – это небольшая ссылка, не видимая для пользователя (например, ссылка-пиксель белого цвета), переход по которой детектируется сервером, после чего сервер банит IP, с которого пришел запрос.
Я защищаюсь от такого рода «мин» способом, достаточно простым: я заранее загружаю список URL, и заставляю скрипт идти по конкретному и конечному списку адресов, никуда не переходя.
В C++17 (нет-нет, Питон скоро будет, вы правильно зашли!) появляется новый синтаксис для оператора if , позволяющий объявлять переменные прямо в заголовке блока. Это довольно удобно, поскольку конструкции вида
довольно общеупотребительны. Код выше лёгким движением руки программиста (и тяжёлым движением руки комитета по стандартизации) превращается в:
Стало чуть-чуть лучше, хотя всё ещё не выглядит идеально. В Python нет и такого, но если вы ненавидите if в Python-коде так же сильно, как я, и хотите научиться быстро писать простые парсеры, то добро пожаловать под кат. В этой статье мы попытаемся написать короткий и изящный парсер для JSON на Python 2 (без каких-либо дополнительных модулей, конечно же).
Парсинг (по-русски «синтаксический анализ») — это бессмертная задача разобрать и преобразовать в осмысленные единицы нечто, написанное на некотором фиксированном языке, будь то язык программирования, язык разметки, язык структурированных запросов или главный язык жизни, Вселенной и всего такого. Типичная последовательность этапов решения задачи выглядит примерно так:
Описать язык
- . Конечно, сначала надо определиться, какую именно задачу мы решаем. Обычно описание языка — это очередная вариация формы Бэкуса-Наура. (Вот, например, описание грамматики Python, использующееся при построении его парсера.) При этом устанавливаются как правила «построения предложений» в языке, так и правила определения валидных слов.
Разбить ввод на токены. Пишется лексический анализатор (в народе токенайзер), который разбивает входную строку или файл на последовательность токенов, то есть валидных слов нашего языка (или ноет, что это нельзя сделать).
Проверить синтаксис и построить синтаксическое дерево. Проверяем, соответствует ли последовательность токенов описанию нашего языка. Здесь в ход идут алгоритмы вроде метода рекурсивного спуска. Каждое валидное предложение языка включает какое-то конечное количество валидных слов или других валидных предложений; если токены смогли сложиться в стройную картину, то на выходе мы автоматически получаем дерево, которое и называется абстрактным синтаксическим деревом.
- Сделать, наконец, работу. У вас есть синтаксическое дерево и вы можете наконец сделать то, что хотели: посчитать значение арифметического выражения, организовать запрос в БД, скомпилировать программу, отобразить веб-страницу и так далее.
Вообще область эта изучена вдоль и поперёк и полна замечательных результатов, и по ней написаны сотни (возможно, хороших) книг. Однако, теоретическая разрешимость задачи и написание кода — не одно и то же.
Модельная задача
Написание парсера проиллюстрируем на простом, но не до конца тривиальном примере — парсинге JSON. Грамматика выглядит примерно так:
Здесь нет правил для string и number — они, вместе со всеми строками в кавычках, будут нашими токенами.
Полноценный токенайзер мы писать не станем (это скучно и не совсем тема статьи) — будем работать с целой строкой и бить её на токены по мере необходимости. Напишем две первые функции:
(Я обещал без if’ов, но это последние, чесслово!)
Для всего остального напишем одну функцию, генерящую простенькие функции-парсеры:
Итого, по какому принципу мы строим наши функции:
- Они принимают строку, которую нужно парсить.
- Они возвращают пару (результат, оставшаяся_строка) при успехе (то есть когда требуемая конструкция нашлась в начале строки) и None при провале.
- Они отправляют в небытие все пробельные символы между токенами. (Не делайте так, если пишете парсер Питона!)
Собственно, на этих трёх функциях проблемы с токенами решены, и мы можем перейти к интересной части.
Парсим правило с ветвлением
Как должна выглядеть функция parse_value , соответствующая грамматике выше? Обычно как-то так:
Ну уж нет, эти if достали меня!
Давайте поменяем три функции выше самым неожиданным образом: заменим return на yield ! Теперь они возвращают генераторы — пустые, если парсинг не удался, и ровно с одним элементом, если удался. Да-да, мы разворачиваем на 90 градусов наш принцип номер 2: все наши функции мы будем теперь писать в таком стиле:
Во что же превратится наша parse_value ? На первый взгляд во что-то такое:
Но на второй взгляд мы увидим, что каждая опция может занимать всего одну строчку!
При этом эффективность остаётся на прежнем уровне — каждая функция начнёт выполняться (а стало быть, делать работу, проверяя регулярные выражения) только тогда, когда предыдущая не даст результата. return гарантирует, что лишняя работа не будет выполнена, если где-то в середине списка парсинг удался.
Парсим последовательности конструкций
Перейдём к следующему номеру нашей программы — функции parse_array . Выглядеть она должна как-то так:
Ни одного if , как и обещано, но что-то всё равно не так… Давайте напишем небольшую вспомогательную функцию, которая поможет нам соединять функции-парсеры в последовательности подобно тому, как chain помогла соединять их в режиме «или». Эта функция должна будет аккуратно брать все результаты и вернуть все первые элементы результатов (результаты анализа) и последний второй элемент (оставшуюся непроанализированной часть строки). Мой вариант выглядит так:
С этим мощным (пусть и страшноватым) инструментом наша функция перепишется в виде:
Ну а дописать функцию parse_comma_separated_values — раз плюнуть:
Приведёт ли такое решение к бесконечной рекурсии? Нет! Однажды функция parse_comma не найдёт очередной запятой, и до последующей parse_comma_separated_values выполнение уже не дойдёт.
Идём дальше! Объект:
Ну, что там дальше?
Собственно, всё! Остаётся добавить простую интерфейсную функцию:
130 строк. Попробуем запустить:
Заключение
Конечно, я рассмотрел далеко не все ситуации, которые могут возникнуть при написании парсеров. Иногда программисту может потребоваться ручное управление выполнением, а не запуск последовательности chain ов и sequence ов. К счастью, это не так неудобно в рассмотренном подходе, как может показаться. Так, если нужно попытаться распарсить необязательную конструкцию и сделать действие в зависимости от её наличия, можно написать:
Здесь мы пользуемся малопопулярной фишкой Питона — блоком else у циклов, который выполняется, если цикл дошёл до конца без break . Это выглядит не так привлекательно, как наш код в статье, но точно не хуже, чем те if , от которых мы столь изящно избавились.
Несмотря на неполноту и неакадемичность изложения, я надеюсь, что эта статья будет полезна начинающим программистам, а может, даже удивит новизной подхода программистов продвинутых. При этом я прекрасно отдаю себе отчёт, что это просто новая форма для старого доброго рекурсивного спуска; но если программирование — это искусство, разве не важна в нём форма если не наравне, то хотя бы в степени, близкой к содержанию.
Как обычно, не откладывая пишите в личку обо всех обнаруженных неточностях, орфографических, грамматических и фактических ошибках — иначе я сгорю от стыда!