
Содержание

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области. Последние версии этой программы в плане возможностей практически ничем не уступают специализированным приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие особенности работы с ними, а также подробнее остановимся на отдельных наиболее полезных инструментах.
Статистические функции
Как и любые другие функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид постоянных чисел, ссылок на ячейки или массивы.
Выражения можно вводить вручную в определенную ячейку или в строку формул, если хорошо знать синтаксис конкретного из них. Но намного удобнее воспользоваться специальным окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» или с помощью кнопок «Библиотеки функций» на ленте.
Запустить Мастер функций можно тремя способами:
-
Кликнуть по пиктограмме «Вставить функцию» слева от строки формул.
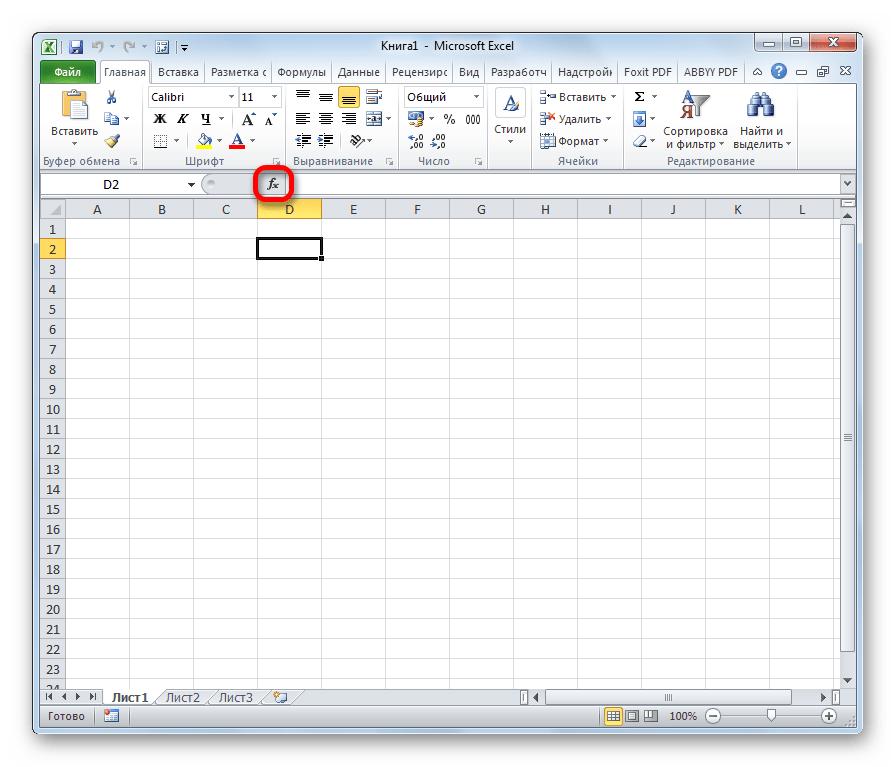
Находясь во вкладке «Формулы», кликнуть на ленте по кнопке «Вставить функцию» в блоке инструментов «Библиотека функций».

При выполнении любого из вышеперечисленных вариантов откроется окно «Мастера функций».
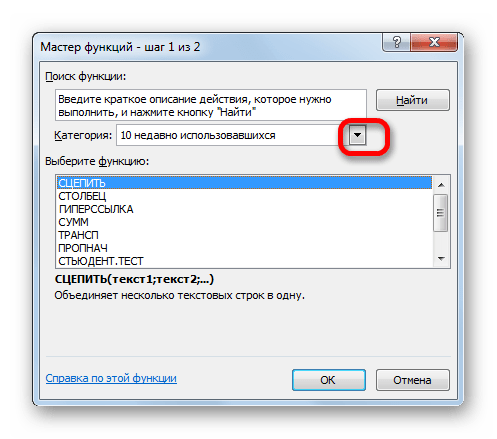
Затем нужно кликнуть по полю «Категория» и выбрать значение «Статистические».

После этого откроется список статистических выражений. Всего их насчитывается более сотни. Чтобы перейти в окно аргументов любого из них, нужно просто выделить его и нажать на кнопку «OK».

Для того, чтобы перейти к нужным нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопке «Другие функции». В открывшемся списке выбираем категорию «Статистические». Откроется перечень доступных элементов нужной нам направленности. Для перехода в окно аргументов достаточно кликнуть по одному из них.

Оператор МАКС предназначен для определения максимального числа из выборки. Он имеет следующий синтаксис:

В поля аргументов нужно ввести диапазоны ячеек, в которых находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в которой находится сама.
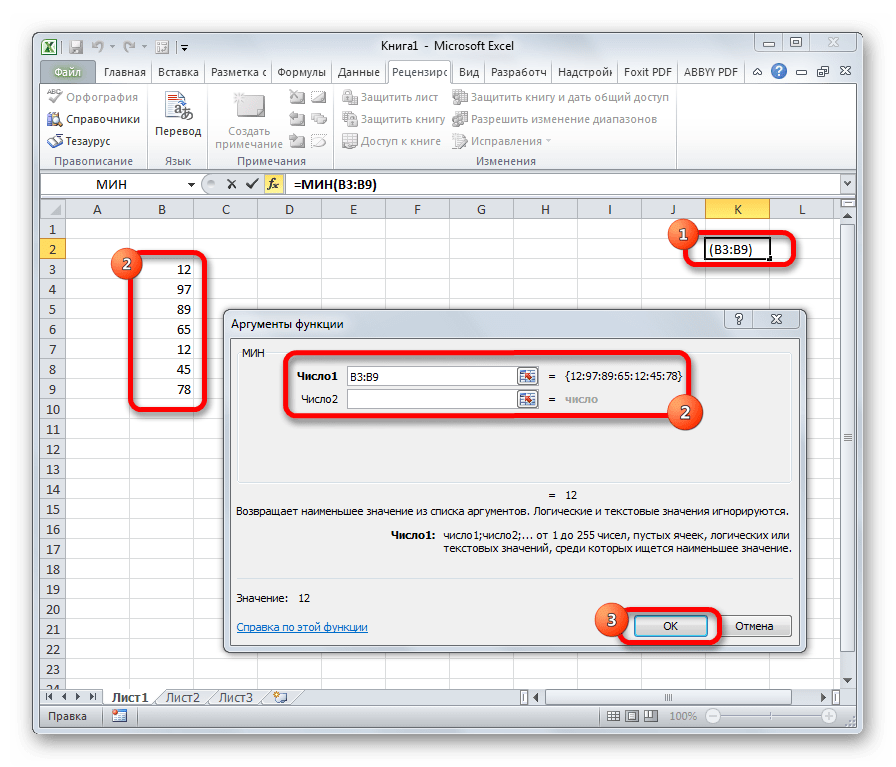
По названию функции МИН понятно, что её задачи прямо противоположны предыдущей формуле – она ищет из множества чисел наименьшее и выводит его в заданную ячейку. Имеет такой синтаксис:
СРЗНАЧ
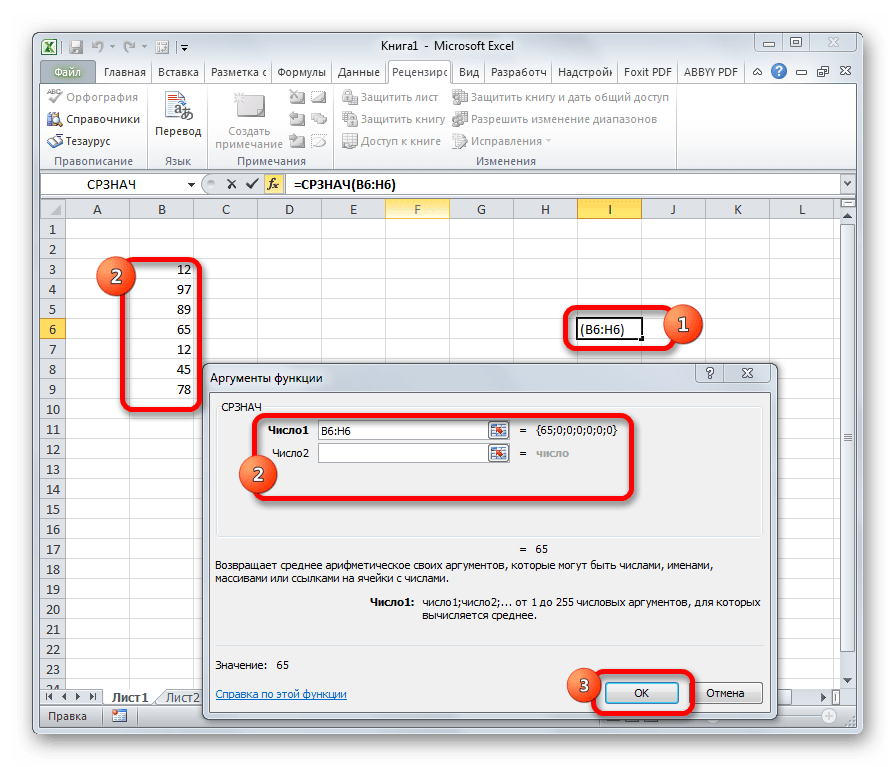
Функция СРЗНАЧ ищет число в указанном диапазоне, которое ближе всего находится к среднему арифметическому значению. Результат этого расчета выводится в отдельную ячейку, в которой и содержится формула. Шаблон у неё следующий:
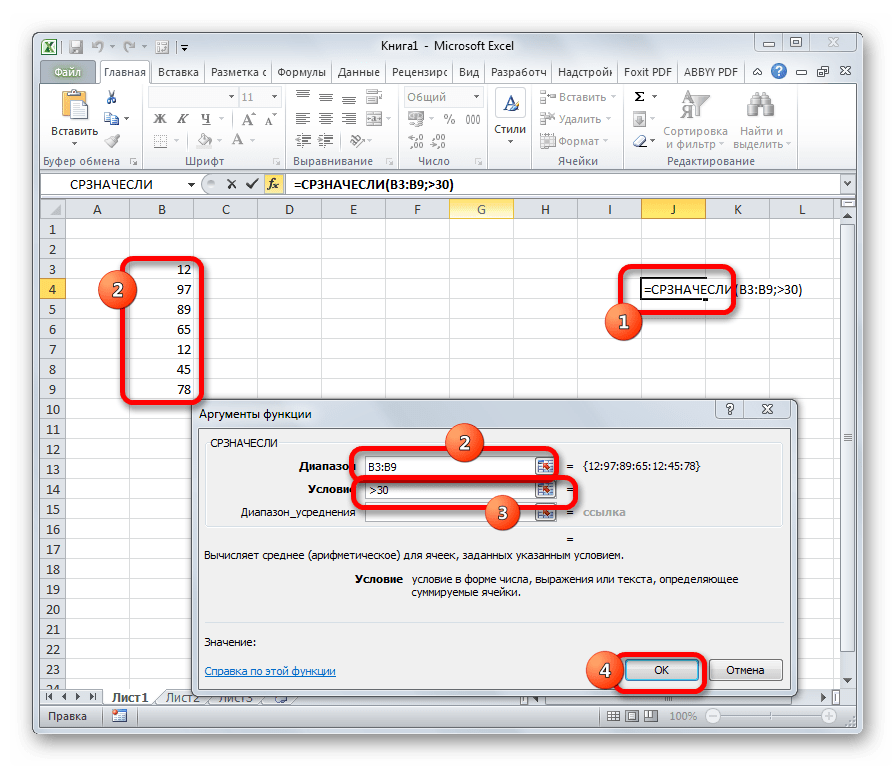
СРЗНАЧЕСЛИ
Функция СРЗНАЧЕСЛИ имеет те же задачи, что и предыдущая, но в ней существует возможность задать дополнительное условие. Например, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Кроме того, в качестве необязательного аргумента может быть добавлен диапазон усреднения. Синтаксис следующий:
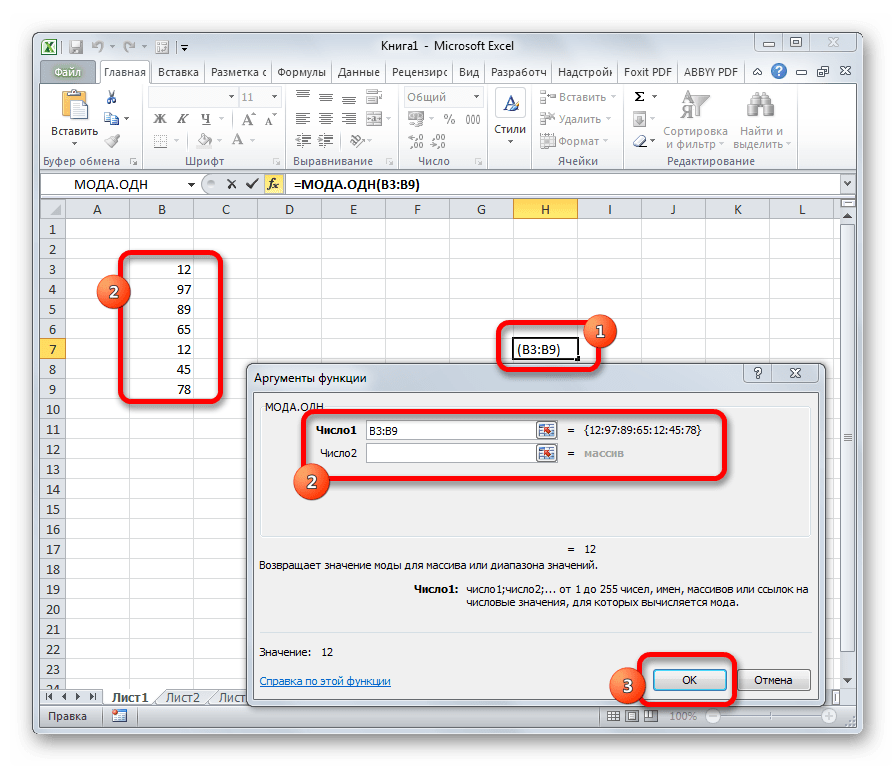
МОДА.ОДН
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается чаще всего. В старых версиях Эксель существовала функция МОДА, но в более поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Впрочем, старый вариант тоже остался в отдельной группе, в которой собраны элементы из прошлых версий программы для обеспечения совместимости документов.
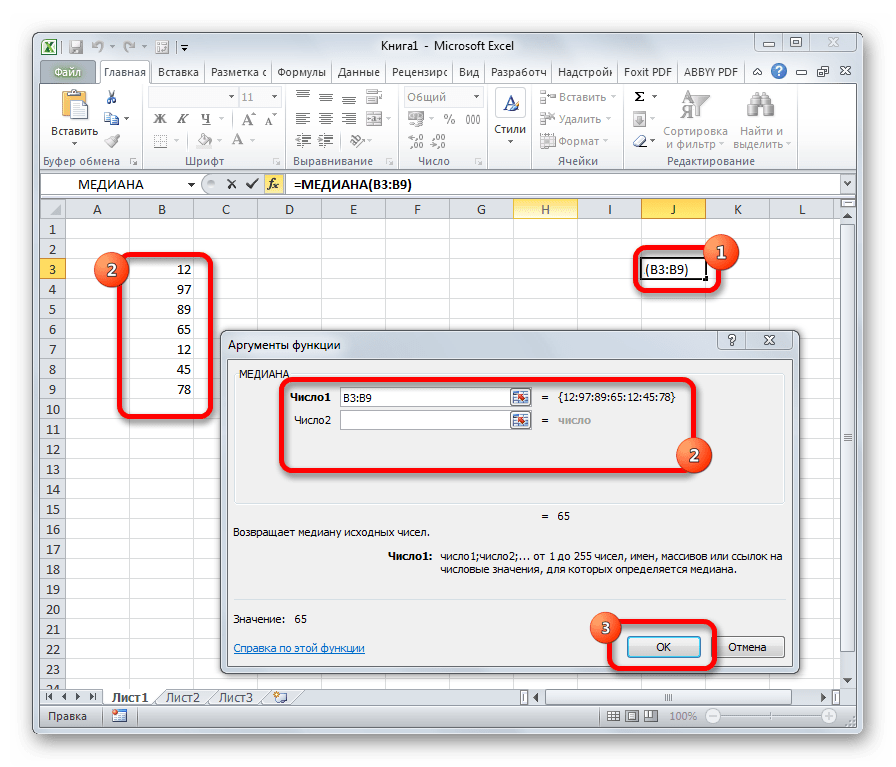
МЕДИАНА
Оператор МЕДИАНА определяет среднее значение в диапазоне чисел. То есть, устанавливает не среднее арифметическое, а просто среднюю величину между наибольшим и наименьшим числом области значений. Синтаксис выглядит так:
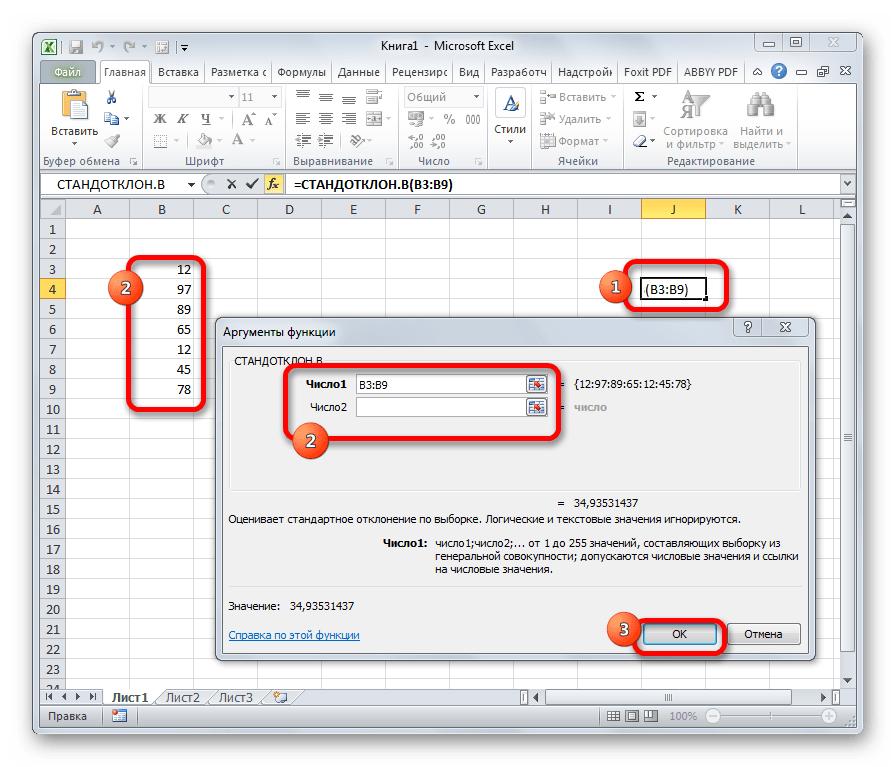
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старых версий программы. Сейчас используются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Первая из них предназначена для вычисления стандартного отклонения выборки, а вторая – генеральной совокупности. Данные функции используются также для расчета среднего квадратичного отклонения. Синтаксис их следующий:
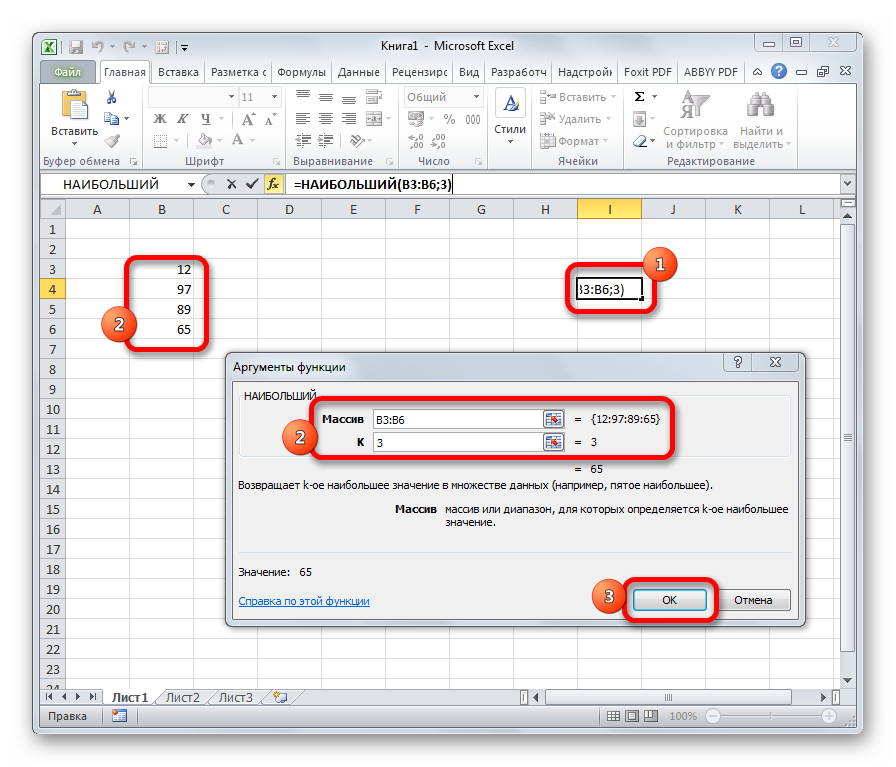
НАИБОЛЬШИЙ
Данный оператор показывает в выбранной ячейке указанное в порядке убывания число из совокупности. То есть, если мы имеем совокупность 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку вернет третье по величине число. В данном случае, это 65. Синтаксис оператора такой:
В данном случае, k — это порядковый номер величины.
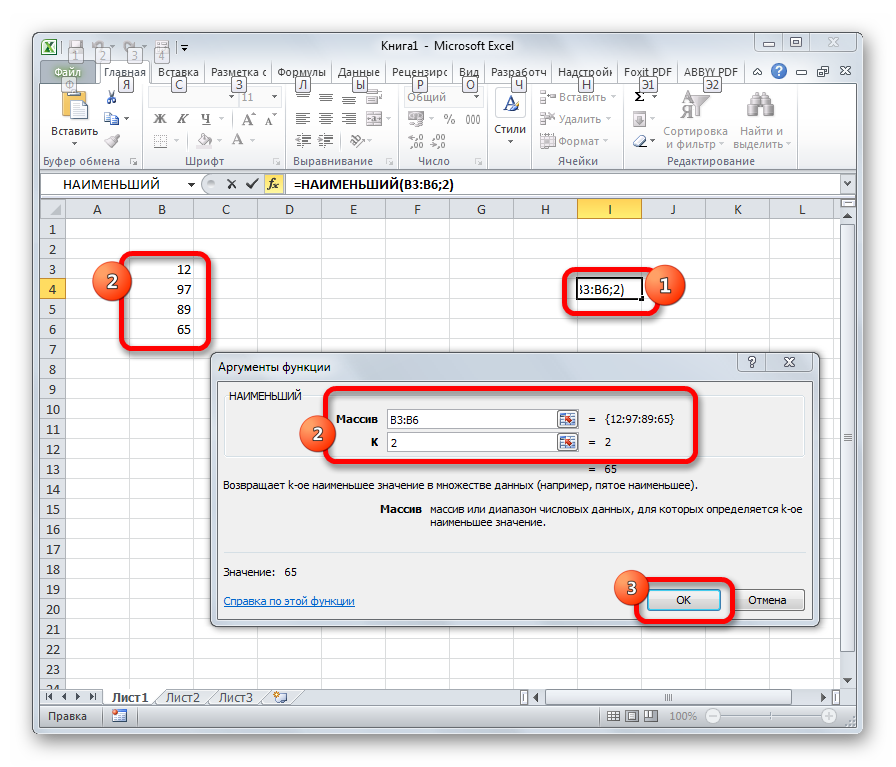
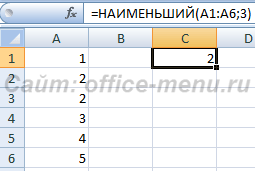
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предыдущего оператора. В ней также вторым аргументом является порядковый номер числа. Вот только в данном случае порядок считается от меньшего. Синтаксис такой:
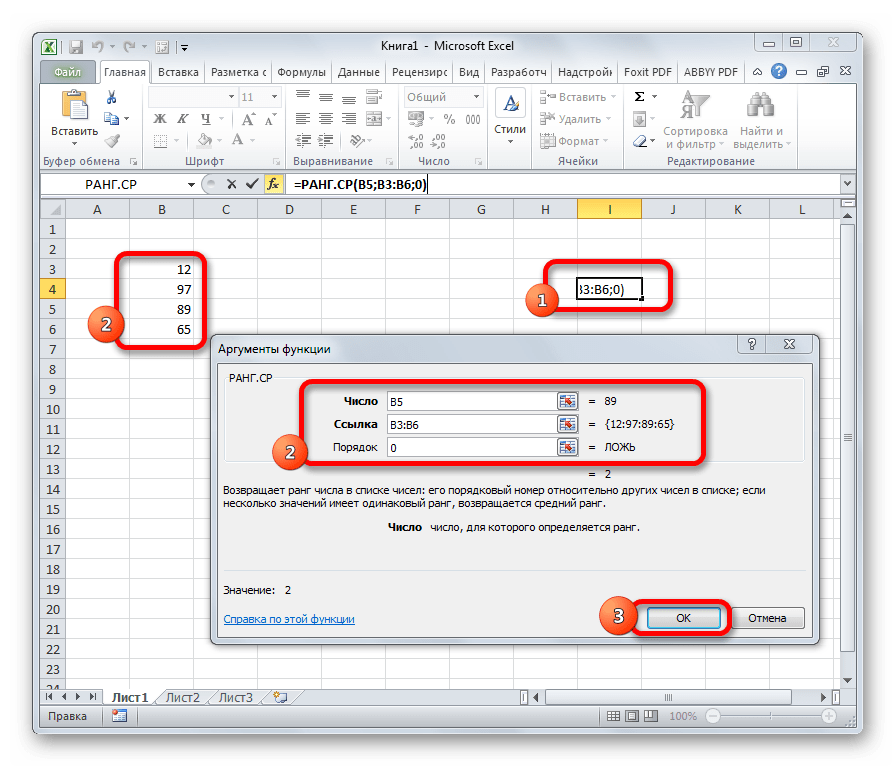
РАНГ.СР
Эта функция имеет действие, обратное предыдущим. В указанную ячейку она выдает порядковый номер конкретного числа в выборке по условию, которое указано в отдельном аргументе. Это может быть порядок по возрастанию или по убыванию. Последний установлен по умолчанию, если поле «Порядок» оставить пустым или поставить туда цифру 0. Синтаксис этого выражения выглядит следующим образом:
Выше были описаны только самые популярные и востребованные статистические функции в Экселе. На самом деле их в разы больше. Тем не менее, основной принцип действий у них похожий: обработка массива данных и возврат в указанную ячейку результата вычислительных действий.
Отблагодарите автора, поделитесь статьей в социальных сетях.
В данной статье будет рассмотрено несколько статистических функций приложения Excel:
Функция МАКС
Возвращает максимальное числовое значение из списка аргументов.
Синтаксис: =МАКС(число1; [число2]; …), где число1 является обязательным аргументом, все последующие аргументы (до число255) необязательны. Аргумент может принимать числовые значения, ссылки на диапазоны и массивы. Текстовые и логические значения в диапазонах и массивах игнорируются.
=МАКС(<1;2;3;4;0;-5;5;"50">) – возвращает результат 5, при этом строка «50» игнорируется, т.к. задана в массиве.
=МАКС(1;2;3;4;0;-5;5;"50") – результатом функции будет 50, т.к. строка явно задана в виде отдельного аргумента и может быть преобразована в число.
=МАКС(-2; ИСТИНА) – возвращает 1, т.к. логическое значение задано явно, поэтому не игнорируется и преобразуется в единицу.
Функция МИН
Возвращает минимальное числовое значение из списка аргументов.
Синтаксис: =МИН(число1; [число2]; …), где число1 является обязательным аргументом, все последующие аргументы (до число255) необязательны. Аргумент может принимать числовые значения, ссылки на диапазоны и массивы. Текстовые и логические значения в диапазонах и массивах игнорируются.
=МИН(<1;2;3;4;0;-5;5;"-50">) – возвращает результат -5, текстовая строка игнорируется.
=МИН(1;2;3;4;0;-5;5;"-50") – результатам функции будет -50, так как строка «-50» задана в виде отдельного аргумента и может быть преобразована в число.
=МИН(5; ИСТИНА) – возвращает 1, так как логическое значение задано явно в виде аргумента, поэтому не игнорируется и преобразуется в единицу.
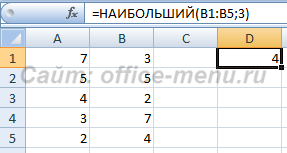
Функция НАИБОЛЬШИЙ
Возвращает значение элемента, являвшегося n-ым наибольшим, из указанного множества элементов. Например, второй наибольший, четвертый наибольший.
Синтаксис: =НАИБОЛЬШИЙ(массив; n), где
- массив – диапазон ячеек либо массив элементов, содержащий числовые значения. Текстовые и логические значения игнорируются.
- n – натуральное число (кроме нуля), указывающее позицию элемента в порядке убывания. Если задать дробное число, то оно округляется до целого в большую сторону (дробные числа меньше единицы возвращают ошибку). Если аргумент превышает количество элементов множества, то функция возвращает ошибку.
Массив или диапазон НЕ обязательно должен быть отсортирован.
На изображении приведено 2 диапазона. Они полностью совпадают, кроме того, что в первом столбце диапазон отсортирован по убыванию, он представлен для наглядности. Функция ссылается на диапазон ячеек во втором столбце и возвращает элемент, являющийся 3 наибольшим значением.
В данном примере используется диапазон с повторяющимися значениями. Видно, что ячейкам не назначаются одинаковые ранги, в случае их равенства.

Функция НАИМЕНЬШИЙ
Возвращает значение элемента, являвшегося n-ым наименьшим, из указанного множества элементов. Например, третий наименьший, шестой наименьший.
Синтаксис: =НАИМЕНЬШИЙ(массив; n), где
- массив – диапазон ячеек либо массив элементов, содержащий числовые значения. Текстовые и логические значения игнорируются.
- n – натуральное число (кроме нуля), указывающее позицию элемента в порядке возрастания. Если задать дробное число, то оно округляется до целого в меньшую сторону (дробные числа меньше единицы возвращают ошибку). Если аргумент превышает количество элементов множества, то функция возвращает ошибку.
Массив или диапазон НЕ обязательно должен быть отсортирован.
Функция РАНГ
Возвращает позицию элемента в списке по его значению, относительно значений других элементов. Результатом функции будет не индекс (фактическое расположение) элемента, а число, указывающее, какую позицию занимал бы элемент, если список был отсортирован либо по возрастанию либо по убыванию.
По сути, функция РАНГ выполняет обратное действие функциям НАИБОЛЬШИЙ и НАИМЕНЬШИЙ, т.к. первая находит ранг по значению, а последние находят значение по рангу.
Текстовые и логические значения игнорируются.
Синтаксис: =РАНГ(число; ссылка; [порядок]), где
- число – обязательный аргумент. Числовое значение элемента, позицию которого необходимо найти.
- ссылка – обязательный аргумент, являющийся ссылкой на диапазон со списком элементов, содержащих числовые значения.
- порядок – необязательный аргумент. Логическое значение, отвечающее за тип сортировки:
- ЛОЖЬ – значение по умолчанию. Функция проверяет значения по убыванию.
- ИСТИНА – функция проверяет значения по возрастанию.
Если в списке отсутствует элемент с указанным значением, то функцией возвращается ошибка #Н/Д.
Если два элемента имеют одинаковое значение, то возвращается ранг первого обнаруженного.
Функция РАНГ присутствует в версиях Excel, начиная с 2010, только для совместимости с более ранними версиями. Вместо нее внедрены новые функции, обладающие тем же синтаксисом:
- РАНГ.РВ – полная идентичность функции РАНГ. Добавленное окончание «.РВ», сообщает о том, что, в случае обнаружения элементов с равными значениями, возвращается высший ранг, т.е. самого первого обнаруженного;
- РАНГ.СР – окончание «.СР», сообщает о том, что, в случае обнаружения элементов с равными значениями, возвращается их средний ранг.
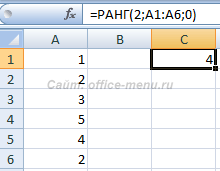
В данном случае используется возврат ранга при проверке диапазона значений по возрастанию.
![]()
На следующем изображении отображено использование функции с проверкой значений по убыванию. Так как в диапазоне имеется 2 ячейки со значением 2, то возвращается ранг первой обнаруженной в указанном порядке.
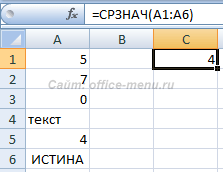
Функция СРЗНАЧ
Возвращает среднее арифметическое значение заданных аргументов.
Синтаксис: =СРЗНАЧ(число1; [число2]; …), где число1 является обязательным аргументом, все последующие аргументы (до число255) необязательны. Аргумент может принимать числовые значения, ссылки на диапазоны и массивы. Текстовые и логические значения в диапазонах и массивах игнорируются.
Результатом выполнения функции из примера будет значение 4, т.к. логические и текстовые значения будут проигнорированы, а (5 + 7 + 0 + 4)/4 = 4.
Функция СРЗНАЧА
Аналогична функции СРЗНАЧ за исключением того, что истинные логические значения в диапазонах приравниваются к 1, а ложные значения и текст приравнивается к нулю.
Возвращаемое значение в следующем примере 2,833333, так как текстовые и логические значения принимаются за ноль, а логическое ИСТИНА приравнивается к единице. Следовательно, (5 + 7 + 0 + 0 + 4 + 1)/6 = 2,833333.

Функция СРЗНАЧЕСЛИ
Вычисляет среднее арифметическое значение для ячеек, отвечающих заданному условию.
Синтаксис: =СРЗНАЧЕСЛИ(диапазон; условие; [диапазон_усреднения]), где
- диапазон – обязательный аргумент. Диапазон ячеек для проверки.
- условие – обязательный аргумент. Значение либо условие проверки. Для текстовых значений могут быть использованы подстановочные символы (* и ?). Условия типа больше, меньше записываются в кавычках.
- диапазон_усреднения – необязательный аргумент. Ссылка на ячейки с числовыми значениями для определения среднего арифметического. Если данный аргумент опущен, то используется аргумент «диапазон».
Необходимо узнать среднее арифметическое для чисел, которые больше 0. Так как для расчета представлено всего 3 числа, из которых 2 являются нулем, то остается только одно значение, которое и является результатом выполнения функция.
Также в функции не используется последний аргумент, поэтому вместо него принимается диапазон из первого.

В следующем примере рассматривается таблица с приведением заработной платы работников. Необходимо узнать среднюю заработную плату для каждой должности.
Функция СРЗНАЧЕСЛИМН
Возвращает среднее арифметическое для ячеек, отвечающих одному либо множеству условий.
Синтаксис: =СРЗНАЧЕСЛИМН(диапазон_усреднения; диапазон_условия1; условие1; [диапазон_условия2]; [условие2]; …), где
- диапазон_усреднения – обязательный аргумент. Ссылка на ячейки с числовыми значениями для определения среднего арифметического.
- диапазон_условия1 – обязательный аргумент. Диапазон ячеек для проверки.
- условие1 – обязательный аргумент. Значение либо условие проверки. Для текстовых значений могут быть использованы подстановочные символы (* и ?). Условия типа больше, меньше заключаются в кавычки.
Все последующие аргументы от диапазон_условия2 и условие2 до диапазон_условия127 и условие127 являются необязательными.
Используем таблицу из примера предыдущей функции с добавлением городов для сотрудников. Выведем среднюю заработную плату для электриков в городе Москва.
Результат выполнения функции 25 000.
Функция принимает в расчет только те значения, которые подходят под все условия.
Функция СЧЁТ
Подсчитывает количество числовых значений в диапазоне.
Синтаксис: =СЧЁТ(значение1; [значение2]; …), где значение1 – обязательный аргумент, принимающий значение, ссылку на ячейку, диапазон ячеек или массив. Аргументы от значение2 до значение255 являются необязательными и аналогичными значение1.
Логические значения в диапазонах и массивах игнорируются. Если такое значение задано явно в аргументе, то оно учитывается как число.
=СЧЁТ(1; 2; "5") – результат функции 3, т.к. строка «5» конвертируется в число.
=СЧЁТ(<1; 2; "5">) – результатом выполнения функции будет значение 2, так как, в отличие от первого примера, число в виде строки записано в массиве, поэтому не будет преобразовано.
=СЧЁТ(1; 2; ИСТИНА) – результат функции 3. Если бы логическое значение находилось бы в массиве, то оно не засчиталось как число.
Функция СЧЁТЕСЛИ
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию.
Синтаксис: =СЧЁТЕСЛИ(диапазон; критерий), где
- диапазон – обязательный аргумент. Принимает ссылку на диапазон ячеек для проверки на условие.
- критерий – обязательный аргумент. Критерий проверки, содержащий значение либо условия типа больше, меньше, которые необходимо заключать в кавычки. Для текстовых значений можно использовать подстановочные символы (* и ?).
В данном случае необходимо подсчитать количество человек с окладом свыше 4000 рублей.

Функция СЧЁТЕСЛИМН
Возвращает количество ячеек в диапазоне, удовлетворяющих условию либо множеству условий.
Функция аналогична функции СЧЁТЕСЛИ, за исключением того, что может содержать до 127 диапазонов и критериев, где первый является обязательным, а последующие – нет.
Синтаксис: =СЧЁТЕСЛИМН(диапазон1; критерий1; [диапазон2]; [критерий2]; …).
На рисунке изображено использование функции СЧЁТЕСЛИМН, где подсчитывается количество человек, имеющих оклад свыше 4000 рублей и проживающих в Москве и Московской области. При этом для последнего условия используется подстановочный символ *.

Функция СЧЁТЗ
Подсчитывает непустые ячейки в указанном диапазоне.
Синтаксис: =СЧЁТЗ(значение1; [значение2]; …), где значение1 является обязательным аргумент, все последующие аргументы до значение255 необязательны. В качестве значения может содержаться ссылка на ячейку или диапазон ячеек.
Ячейки, содержащие пустые строки (=""), засчитываются как НЕпустые.
Функция возвращает значение 4, т.к. ячейка A3 содержит текстовую функцию, возвращающую пустую строку.
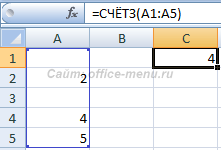
Функция СЧИТАТЬПУСТОТЫ
Подсчитывает пустые ячейки в указанном диапазоне.
Синтаксис: =СЧИТАТЬПУСТОТЫ(диапазон), где единственный аргумент является обязательным и принимает ссылку на диапазон ячеек для проверки.
Пустые строки (="") засчитываются как пустые.
Функция возвращает значение 2, несмотря на то, что ячейка A3 содержит текстовую функцию, возвращающую пустую строку.
![]()
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы мы могли развивать его дальше.
У Вас недостаточно прав для комментирования.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке) .
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего.
Возвращает среднее арифметическое аргументов.
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения.
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют данному условию.
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям.
БЕТА.РАСП
Возвращает интегральную функцию бета-распределения.
БЕТА.ОБР
Возвращает обратную интегральную функцию указанного бета-распределения.
БИНОМ.РАСП
Возвращает отдельное значение вероятности биномиального распределения.
БИНОМ.РАСП.ДИАП

Возвращает вероятность пробного результата с помощью биномиального распределения.
БИНОМ.ОБР
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему.
ХИ2.РАСП
Возвращает интегральную функцию плотности бета-вероятности.
ХИ2.РАСП.ПХ
Возвращает одностороннюю вероятность распределения хи-квадрат.
ХИ2.ОБР
Возвращает интегральную функцию плотности бета-вероятности.
ХИ2.ОБР.ПХ
Возвращает обратное значение односторонней вероятности распределения хи-квадрат.
ХИ2.ТЕСТ
Возвращает тест на независимость.
ДОВЕРИТ.НОРМ
Возвращает доверительный интервал для среднего значения по генеральной совокупности.
ДОВЕРИТ.СТЬЮДЕНТ
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента.
Возвращает коэффициент корреляции между двумя множествами данных.
Подсчитывает количество чисел в списке аргументов.
Подсчитывает количество значений в списке аргументов.
Подсчитывает количество пустых ячеек в диапазоне.
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию.
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям.
КОВАРИАЦИЯ.Г
Возвращает ковариацию, среднее произведений парных отклонений.
КОВАРИАЦИЯ.В
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных.
Возвращает сумму квадратов отклонений.
ЭКСП.РАСП
Возвращает экспоненциальное распределение.
F.РАСП
Возвращает F-распределение вероятности.
F.РАСП.ПХ
Возвращает F-распределение вероятности.
F.ОБР
Возвращает обратное значение для F-распределения вероятности.
F.ОБР.ПХ
Возвращает обратное значение для F-распределения вероятности.
F.ТЕСТ
Возвращает результат F-теста.
Возвращает преобразование Фишера.
Возвращает обратное преобразование Фишера.
Возвращает значение линейного тренда.
Примечание: В Excel_2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями.
ПРЕДСКАЗ.ETS

Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS).
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ
Возвращает доверительный интервал для прогнозной величины на указанную дату.
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду.
ПРЕДСКАЗ.ETS.СТАТ
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда.
ПРЕДСКАЗ.ЛИНЕЙН
Возвращает будущее значение на основе существующих значений.
Возвращает распределение частот в виде вертикального массива.
ГАММА
Возвращает значение функции гамма
ГАММА.РАСП
ГАММА.ОБР
Возвращает обратное значение интегрального гамма-распределения.
Возвращает натуральный логарифм гамма-функции, Γ(x).
ГАММАНЛОГ.ТОЧН
Возвращает натуральный логарифм гамма-функции, Γ(x).
ГАУСС
Возвращает значение на 0,5 меньше стандартного нормального распределения.
Возвращает среднее геометрическое.
Возвращает значения в соответствии с экспоненциальным трендом.
Возвращает среднее гармоническое.
Возвращает гипергеометрическое распределение.
Возвращает отрезок, отсекаемый на оси линией линейной регрессии.
Возвращает эксцесс множества данных.
Возвращает k-ое наибольшее значение в множестве данных.
Возвращает параметры линейного тренда.
Возвращает параметры экспоненциального тренда.
ЛОГНОРМ.РАСП
Возвращает интегральное логарифмическое нормальное распределение.
ЛОГНОРМ.ОБР
Возвращает обратное значение интегрального логарифмического нормального распределения.
Возвращает наибольшее значение в списке аргументов.
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения.
МАКСЕСЛИ
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек.
Возвращает медиану заданных чисел.
Возвращает наименьшее значение в списке аргументов.
МИНЕСЛИ
Возвращает минимальное значение среди ячеек, заданному набору условий или условия.
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения.
МОДА.НСК
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных.
МОДА.ОДН
Возвращает значение моды набора данных.
ОТРБИНОМ.РАСП
Возвращает отрицательное биномиальное распределение.
НОРМ.РАСП
Возвращает нормальное интегральное распределение.
НОРМ.ОБР
Возвращает обратное значение нормального интегрального распределения.
НОРМ.СТ.РАСП
Возвращает стандартное нормальное интегральное распределение.
НОРМ.СТ.ОБР
Возвращает обратное значение стандартного нормального интегрального распределения.
Возвращает коэффициент корреляции Пирсона.
ПРОЦЕНТИЛЬ.ИСКЛ
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа).
ПРОЦЕНТИЛЬ.ВКЛ
Возвращает k-ю процентиль для значений диапазона.
ПРОЦЕНТРАНГ.ИСКЛ
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы).
ПРОЦЕНТРАНГ.ВКЛ
Возвращает процентную норму значения в наборе данных.
Возвращает количество перестановок для заданного числа объектов.
ПЕРЕСТА
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов.
ФИ
Возвращает значение функции плотности для стандартного нормального распределения.
ПУАССОН.РАСП
Возвращает распределение Пуассона.
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов.
КВАРТИЛЬ.ИСКЛ
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы.
КВАРТИЛЬ.ВКЛ
Возвращает квартиль набора данных.
РАНГ.СР
Возвращает ранг числа в списке чисел.
РАНГ.РВ
Возвращает ранг числа в списке чисел.
Возвращает квадрат коэффициента корреляции Пирсона.
Возвращает асимметрию распределения.
СКОС.Г
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего.
Возвращает наклон линии линейной регрессии.
Возвращает k-ое наименьшее значение в множестве данных.
Возвращает нормализованное значение.
СТАНДОТКЛОН.Г
Вычисляет стандартное отклонение по генеральной совокупности.
СТАНДОТКЛОН.В
Оценивает стандартное отклонение по выборке.
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения.
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения.
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии.
СТЬЮДРАСП
Возвращает процентные точки (вероятность) для t-распределения Стьюдента.
СТЬЮДЕНТ.РАСП.2Х
Возвращает процентные точки (вероятность) для t-распределения Стьюдента.
СТЬЮДЕНТ.РАСП.ПХ
Возвращает t-распределение Стьюдента.
СТЬЮДЕНТ.ОБР
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы.
СТЬЮДЕНТ.ОБР.2Х
Возвращает обратное t-распределение Стьюдента.
СТЬЮДЕНТ.ТЕСТ
Возвращает вероятность, соответствующую проверке по критерию Стьюдента.
Возвращает значения в соответствии с линейным трендом.
Возвращает среднее внутренности множества данных.
ДИСП.Г
Вычисляет дисперсию по генеральной совокупности.
ДИСП.В
Оценивает дисперсию по выборке.
Оценивает дисперсию по выборке, включая числа, текст и логические значения.
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения.
ВЕЙБУЛЛ.РАСП
Возвращает распределение Вейбулла.
Z.ТЕСТ
Возвращает одностороннее значение вероятности z-теста.
Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.