
Технический блог специалистов ООО"Интерфейс"
- Главная
- Производительность дисковой подсистемы — краткий ликбез.
Производительность дисковой подсистемы — краткий ликбез.
- Автор: Уваров А.С.
- 08.02.2013

Когда заходит речь о производительности в первую очередь обращают внимание на частоту процессора, скорость памяти, чипсет и т.д. и т.п., про дисковую подсистему если и вспоминают, то мимоходом, чаще всего обращая внимание только на один параметр — скорость линейного чтения. В тоже время именно дисковая подсистема чаще всего становится узким местом в системе. Почему так происходит и как этого избежать мы расскажем в данной статье.
Прежде чем говорить о производительности вспомним как устроен жесткий диск, так как многие особенности и ограничения HDD заложены именно на физическом уровне. Не вдаваясь в подробности, можно сказать что диск состоит из одной или нескольких магнитных пластин над которыми расположен блок магнитных головок, пластины в свою очередь содержат намагниченные концентрические окружности — цилиндры (дорожки), которые в свою очередь состоят из небольших фрагментов — секторов. Сектор — минимальное адресуемое пространство диска, его размер традиционно составляет 512 байт, хотя некоторые современные диски имеют более крупный сектор размером в 4 Кбайт.
Во время вращения диска сектора проходят мимо блока магнитных головок, которые осуществляют запись или чтение информации. Скорость вращения (угловая скорость) диска в конечный момент времени величина постоянная, однако линейная скорость различных участков диска различна. У внешнего края диска она максимальна, у внутреннего — минимальна. Рассмотрим следующий рисунок:
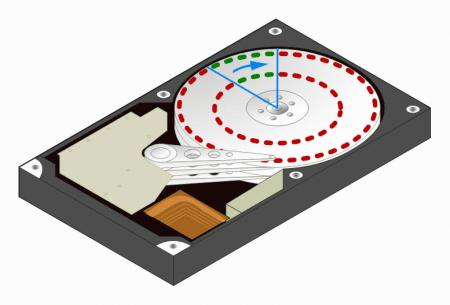
Как видим за один и тот же промежуток времени определенная область диска сделает поворот на один и тот же угол, если мы обозначим эту область в виде сектора, то окажется что в него попадет пять секторов с внешней дорожки и только три с внутренней. Следовательно за данный промежуток времени магнитная головка считает с внешнего цилиндра большее количество информации, чем с внутреннего. На практике это проявляется в том, что график скорости чтения любого диска представляет собой снижающуюся кривую.
Начальные сектора и цилиндры всегда располагаются с внешней стороны, обеспечивая максимальную скорость обмена данными, поэтому рекомендуется размещать системный раздел именно в начале диска.
Теперь перейдем на более высокий уровень — уровень файловой системы. Файловая система оперирует более крупными блоками данных — кластерами. Типичный размер кластера NTFS — 4 Кб или 8 секторов. Получив указание считать определенный кластер диск произведет чтение 8 последовательных секторов, при последовательном расположении данных операционная система даст указание считать данные начиная с кластера 100 и заканчивая кластером 107. Данное действие будет представлять собой одну операцию ввода-вывода (IO), максимальное количество таких операций в секунду (IOPS) конечно и зависит от того, сколько секторов пройдут мимо головки за единицу времени (а также от времени позиционирования головки). Скорость обмена данными измеряется в МБ/с (MBPS) и зависит от того, какое количество данных будет считано за одну операцию ввода-вывода. При последовательном расположении данных скорость обмена будет максимальной, а количество операций ввода-вывода минимально.

Здесь будет не лишним вспомнить о таком параметре как плотность записи, которая выражается в площади необходимой для записи 1 бита данных. Чем выше этот параметр, тем больше данных может вместить одна пластина и тем выше скорость линейного обмена данными. Этим объясняются более высокие скоростные характеристики современных винчестеров, хотя технически они могут ничем не отличаться от более старых моделей. Рисунок ниже иллюстрирует данную ситуацию. Как несложно заметить, при более высокой плотности записи за один и тот-же промежуток времени, при той же самой скорости вращения будет считано/записано большее количество данных

Теперь разберем прямо противоположную ситуацию, нам требуется считать большое количество небольших файлов случайным образом разбросанных по всему диску. В этом случае количество операций ввода-вывода будет велико, а скорость обмена данными низка. Основное время будет занимать ожидание доступа к следующему блоку данных, которое зависит от времени позиционирования головки и задержки из-за вращения диска. Простой пример: если после 100 сектора поступит команда прочитать 98, то придется ждать полный оборот диска, пока появится возможность прочитать данный сектор. Сюда же следует добавить время, которое требуется чтобы физически прочитать нужное количество секторов. Совокупность этих параметров составит время случайного доступа, которое имеет очень большое влияние на производительность винчестера.

Следует отметить, что для ОС и многих серверных задач (СУБД, виртуализация и т.п.) характерен именно случайный доступ с размером блока в 4 Кб (размер кластера), при этом основным показателем производительности будет не скорость линейного обмена данными (MBPS), а максимальное количество операций ввода-вывода в секунду (IOPS). Чем выше этот параметр, тем большее количество данных может быть считано в единицу времени.
Однако количество операций ввода-вывода не может расти бесконечно, это значение очень жестко ограничено сверху физическими показателями винчестера, а именно временем случайного доступа.
А теперь поговорим о фрагментации, суть этого явления общеизвестна, мы же посмотрим на него сквозь призму производительности. Для крупных файлов и линейных нагрузок фрагментация способна значительно снизить производительность, так как последовательный доступ превратится в случайный, что вызовет резкое снижение скорости доступа и также резко увеличит количество операций ввода-вывода.
При случайном характере доступа фрагментация не играет особой роли, так как нет никакой разницы в каком именно месте диска находится тот или иной блок данных.
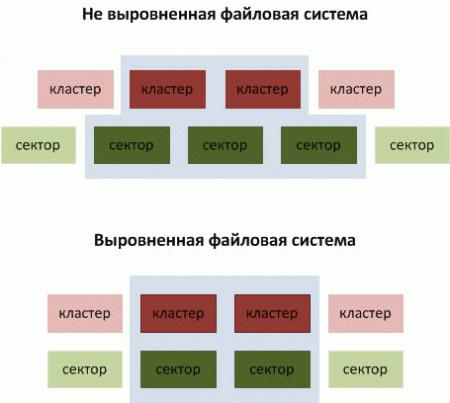
Появление дисков с более крупным 4 Кб сектором стало причиной появления еще одной проблемы: выравнивания файловой системы относительно секторов диска. Здесь возможны два варианта: если файловая система выровнена, то каждому кластеру соответствует сектор, если не выровнена, то каждому кластеру соответствует два смежных сектора. А так как сектор это минимальная адресуемая единица, то для считывания одного кластера потребуется считать не один, а два сектора, что негативно скажется на производительности, особенно при случайном доступе.
Реальная производительность жесткого диска — это всегда баланс между скоростью обмена данными и количеством операций ввода вывода. Для последовательного чтения характерен большой размер пакета данных, который считывается за одну операцию ввода вывода. Максимальная скорость (MBPS) будет достижима при последовательном чтении секторов с внешнего края диска, количество операций ввода-вывода (IOPS) будет при этом минимально — дорожки длинные, позиционировать головку нужно реже, данных при этом считывается больше. На внутренних дорожках линейная скорость будет ниже, количество IO — выше, дорожки короткие, позиционировать головку нужно чаще, данных считывается меньше.
При случайном доступе скорость будет минимальна, так как размер пакета данных очень мал (в худшем случае кластер) и производительность упрется в максимально доступное количество IOPS. Для современных массовых дисков это значение равно около 70 IOPS, нетрудно посчитать, что при случайном доступе с размером пакета в 4 Кб мы получим максимальную скорость не более 0,28 MBPS.
Непонимание этого момента часто приводит к тому, что дисковая подсистема оказывается бутылочным горлышком, которое тормозит работу всей системы. Так, выбирая между двумя дисками с максимальной линейной скоростью в 120 и 150 MBPS, многие не задумываясь выберут второй, не посмотрев на то, что первый диск обеспечивает 70 IOPS, а второй всего 50 IOPS (вполне характерная ситуация для экономичных серий), а потом будут сильно удивляться тому, почему "более быстрый" диск сильно тормозит.
Что будет, если количества IOPS диска окажется недостаточно чтобы обработать все запросы? Возникнет очередь дисковых запросов. На практике все несколько сложнее и очередь диска будет возникать даже в том случае, когда IOPS достаточно. Это связано с тем, что различные процессы, обращающиеся к диску, имеют разный приоритет, а также то, что операции записи всегда имеют приоритет над операциями чтения. Для оценки ситуации существует параметр длина очереди диска, значение которого не должно превышать (по рекомендациям Microsoft)
В любом случае постоянная большая длина очереди говорит о том, что системе недостаточно текущего значения IOPS. Увеличение очереди диска на уже работающих системах говорит либо о увеличении нагрузки, либо о выходе из строя или износе жестких дисков. В любом случае следует задуматься об апгрейде дисковой подсистемы.
На этом мы закончим наш сегодняшний материал, приведенной информации должно быть достаточно для понимания физических процессов, происходящих при работе жесткого диска и того, как они влияют на производительность. В следующих статьях мы рассмотрим, как правильно определить, какое количество IOPS нужно в зависимости от характера нагрузки и как правильно спроектировать дисковую подсистему, чтобы она удовлетворяла предъявляемым требованиям.
Для удобства рассмотрения мы будем использовать скриншот Монитора ресурсов (рис. A), запущенного на производственном сервере под управлением Windows Server 2008 R2. На этом сервере установлен Exchange Server 2010 со всеми ролями, поэтому он нуждается в большой дисковой подсистеме с приемлемой производительностью. (Примечание: как и все другие наши серверы, этот работает в виртуальной машине на базе VMware vSphere 4.1.)
Начнем с общего обзора консоли. Большую часть окна занимают статистические показатели, о которых я подробно расскажу ниже. Справа расположены графики, каждый из которых представляет один из важных показателей производительности дисковой подсистемы.
Ниже я подробно рассмотрю каждый показатель. Я не буду повторяться: если показатель присутствует в нескольких местах, я упомяну его только в первый раз.
Процессы с дисковой активностью
В разделе «Процессы с дисковой активностью» (Processes With Disk Activity) перечислены все запущенные процессы, использующие ресурсы хранения. В списке показано имя исполняемого файла и ряд связанных с ним статистических показателей.
• «Образ» (Image) – имя исполняемого файла. Это имя процесса, активно использующего диск.
• «ИД процесса» (PID) – идентификатор процесса. Может пригодиться для управления процессами с использованием других утилит или для поиска процессов в Диспетчере задач (Task Manager).
• «Чтение (байт/с)» (Read (B/sec)) – среднее количество прочитанных процессом байтов в секунду за последнюю минуту.
• «Запись (байт/с)» (Write (B/sec)) – среднее количество записанных процессом байтов в секунду за последнюю минуту.
• «Всего (байт/с)» (Total (B/sec)) – среднее количество использованных байтов в секунду за последнюю минуту.
Информация, которая приводится в этом разделе, не особенно актуальна для диагностики – она лишь позволяет выяснить, какие процессы потребляют больше всего ресурсов диска. На рис. A, например, можно заметить, что больше всего операций чтения с диска выполняет процесс с именем «DPMRA.exe».
В разделе «Работа диска» (Disk Activity) собраны более полезные для диагностики сведения. Самый ценный показатель – пожалуй, время ответа, поскольку его можно оценить, даже не зная исходной конфигурации дисковой подсистемы.
Справа от названия раздела расположены два небольших индикатора. Зеленый показывает текущий дисковый ввод/вывод (Disk I/O), то есть, количество передаваемых в данный момент данных), а синий – максимум активного времени дисковой подсистемы (Highest Active Time).
• «Файл» (File) – имя файла, используемого процессом. Здесь указывается полный путь к файлу, чтобы его легче было найти.
• «Приоритет ввода/вывода» (I/O Priority) – приоритет операций ввода/вывода.
• «Время ответа (мс)» (Response Time (ms)) – время отклика диска в миллисекундах. Как правило, чем ниже этот показатель, тем лучше. В целом, время ответа менее 10 мс свидетельствует о хорошей производительности. Не страшно, если этот показатель время от времени превышает отметку в 10 мс, но если системе постоянно приходится дожидаться ответа дисковой подсистемы более 20 мс, это может свидетельствовать о наличии проблем, а конечные пользователи в таком случае заметят ощутимое снижение быстродействия. Если время ответа достигает 50 мс и выше, значит, проблема действительно серьезная. На рис. A, как видите, время ответа составляет 5-6 мс, так что дисковая подсистема функционирует исправно, если судить по этому показателю.
В разделе «Запоминающие устройства» (Storage) содержатся следующие сведения:
• «Логический диск» (Logical Disk) – буква диска.
• «Физический диск» (Physical disk) – выбранный для мониторинга физический диск.
• «Активное время (%)» (Active Time (%)) – сколько времени диск проводит, активно обслуживая запросы, в противовес времени простоя. Если активность диска постоянно очень высока (скажем, более 80%), это может указывать на наличие потенциальных проблем, связанных с ресурсами хранения. Если пользователи жалуются на низкое быстродействие, а активное время постоянно составляет 100%, возможно, необходимо увеличить объем дисковой подсистемы или установить более производительные накопители.
• «Свободно (МБ)» (Available Space (MB)) – количество свободного пространства в текущем томе диска.
• «Всего (МБ)» (Total Space (MB)) – общий объем тома.
• «Длина очереди диска» (Disk Queue Length) – средняя длина очереди диска. Длина очереди показывает количество ожидающих выполнения запросов (на чтение и запись) в любой момент времени. Если этот показатель довольно высок, это может свидетельствовать о том, что скорость вращения диска недостаточна для удовлетворения запросов приложений или что дисковая подсистема имеет слишком низкую производительность и не справляется с запросами. Однако чтобы оценить, насколько высок показатель, необходимо хорошо понимать, как создается базовый том в SAN. Каждый диск, из которых складывается базовый том, предоставляет дополнительные ресурсы, которые учитываются при расчете длины очереди (проще говоря, чем больше дисков, тем выше будет длина очереди).
Уровень RAID и размер страйпа тоже влияют на длину очереди, что дополнительно усложняет задачу. Однако если компьютер оснащен всего одним диском, а длина очереди постоянно превышает 2, система нуждается в дополнительных ресурсах хранения. Длина очереди более 5 свидетельствует о наличии серьезных проблем. Если вам известно, из скольких дисков состоит базовый том, умножьте количество дисков на 2, чтобы очень грубо, приблизительно, прикинуть максимально допустимую длину очереди. К примеру, если в системе десять дисков, а длина очереди равна 18, значит, все в порядке.
Графики – очень полезный инструмент. В верхнем графике показана скорость обмена данными между диском и операционной системой за последнюю минуту. Зеленая кривая показывает текущий суммарный ввод/вывод, а синяя – активное время диска за этот период. На остальных графиках показана длина очереди для каждого диска в системе.
На сервере Exchange, который показан в моем примере, используется четыре диска (тома SAN). С учетом структуры базовых томов SAN в этом массиве, никаких проблем, связанных с длиной очереди, не возникает.
Решение
Для удобства рассмотрения мы будем использовать скриншот Монитора ресурсов (рис. A), запущенного на производственном сервере под управлением Windows Server 2008 R2. На этом сервере установлен Exchange Server 2010 со всеми ролями, поэтому он нуждается в большой дисковой подсистеме с приемлемой производительностью. (Примечание: как и все другие наши серверы, этот работает в виртуальной машине на базе VMware vSphere 4.1.)
Начнем с общего обзора консоли. Большую часть окна занимают статистические показатели, о которых я подробно расскажу ниже. Справа расположены графики, каждый из которых представляет один из важных показателей производительности дисковой подсистемы.
Ниже я подробно рассмотрю каждый показатель. Я не буду повторяться: если показатель присутствует в нескольких местах, я упомяну его только в первый раз.
Процессы с дисковой активностью
В разделе «Процессы с дисковой активностью» (Processes With Disk Activity) перечислены все запущенные процессы, использующие ресурсы хранения. В списке показано имя исполняемого файла и ряд связанных с ним статистических показателей.
• «Образ» (Image) – имя исполняемого файла. Это имя процесса, активно использующего диск.
• «ИД процесса» (PID) – идентификатор процесса. Может пригодиться для управления процессами с использованием других утилит или для поиска процессов в Диспетчере задач (Task Manager).
• «Чтение (байт/с)» (Read (B/sec)) – среднее количество прочитанных процессом байтов в секунду за последнюю минуту.
• «Запись (байт/с)» (Write (B/sec)) – среднее количество записанных процессом байтов в секунду за последнюю минуту.
• «Всего (байт/с)» (Total (B/sec)) – среднее количество использованных байтов в секунду за последнюю минуту.
Информация, которая приводится в этом разделе, не особенно актуальна для диагностики – она лишь позволяет выяснить, какие процессы потребляют больше всего ресурсов диска. На рис. A, например, можно заметить, что больше всего операций чтения с диска выполняет процесс с именем «DPMRA.exe».
Работа диска
В разделе «Работа диска» (Disk Activity) собраны более полезные для диагностики сведения. Самый ценный показатель – пожалуй, время ответа, поскольку его можно оценить, даже не зная исходной конфигурации дисковой подсистемы.
Справа от названия раздела расположены два небольших индикатора. Зеленый показывает текущий дисковый ввод/вывод (Disk I/O), то есть, количество передаваемых в данный момент данных), а синий – максимум активного времени дисковой подсистемы (Highest Active Time).
• «Файл» (File) – имя файла, используемого процессом. Здесь указывается полный путь к файлу, чтобы его легче было найти.
• «Приоритет ввода/вывода» (I/O Priority) – приоритет операций ввода/вывода.
• «Время ответа (мс)» (Response Time (ms)) – время отклика диска в миллисекундах. Как правило, чем ниже этот показатель, тем лучше. В целом, время ответа менее 10 мс свидетельствует о хорошей производительности. Не страшно, если этот показатель время от времени превышает отметку в 10 мс, но если системе постоянно приходится дожидаться ответа дисковой подсистемы более 20 мс, это может свидетельствовать о наличии проблем, а конечные пользователи в таком случае заметят ощутимое снижение быстродействия. Если время ответа достигает 50 мс и выше, значит, проблема действительно серьезная. На рис. A, как видите, время ответа составляет 5-6 мс, так что дисковая подсистема функционирует исправно, если судить по этому показателю.
Запоминающие устройства
В разделе «Запоминающие устройства» (Storage) содержатся следующие сведения:
• «Логический диск» (Logical Disk) – буква диска.
• «Физический диск» (Physical disk) – выбранный для мониторинга физический диск.
• «Активное время (%)» (Active Time (%)) – сколько времени диск проводит, активно обслуживая запросы, в противовес времени простоя. Если активность диска постоянно очень высока (скажем, более 80%), это может указывать на наличие потенциальных проблем, связанных с ресурсами хранения. Если пользователи жалуются на низкое быстродействие, а активное время постоянно составляет 100%, возможно, необходимо увеличить объем дисковой подсистемы или установить более производительные накопители.
• «Свободно (МБ)» (Available Space (MB)) – количество свободного пространства в текущем томе диска.
• «Всего (МБ)» (Total Space (MB)) – общий объем тома.
• «Длина очереди диска» (Disk Queue Length) – средняя длина очереди диска. Длина очереди показывает количество ожидающих выполнения запросов (на чтение и запись) в любой момент времени. Если этот показатель довольно высок, это может свидетельствовать о том, что скорость вращения диска недостаточна для удовлетворения запросов приложений или что дисковая подсистема имеет слишком низкую производительность и не справляется с запросами. Однако чтобы оценить, насколько высок показатель, необходимо хорошо понимать, как создается базовый том в SAN. Каждый диск, из которых складывается базовый том, предоставляет дополнительные ресурсы, которые учитываются при расчете длины очереди (проще говоря, чем больше дисков, тем выше будет длина очереди).
Уровень RAID и размер страйпа тоже влияют на длину очереди, что дополнительно усложняет задачу. Однако если компьютер оснащен всего одним диском, а длина очереди постоянно превышает 2, система нуждается в дополнительных ресурсах хранения. Длина очереди более 5 свидетельствует о наличии серьезных проблем. Если вам известно, из скольких дисков состоит базовый том, умножьте количество дисков на 2, чтобы очень грубо, приблизительно, прикинуть максимально допустимую длину очереди. К примеру, если в системе десять дисков, а длина очереди равна 18, значит, все в порядке.
Графики
Графики – очень полезный инструмент. В верхнем графике показана скорость обмена данными между диском и операционной системой за последнюю минуту. Зеленая кривая показывает текущий суммарный ввод/вывод, а синяя – активное время диска за этот период. На остальных графиках показана длина очереди для каждого диска в системе.
На сервере Exchange, который показан в моем примере, используется четыре диска (тома SAN). С учетом структуры базовых томов SAN в этом массиве, никаких проблем, связанных с длиной очереди, не возникает.
Использование Монитора ресурсов (Resource Monitor): центральный процессор
Для удобства рассмотрения мы будем использовать скриншот Монитора ресурсов (рис. A), запущенного на производственном сервере под управлением Windows Server 2008 R2. На этом сервере установлен Exchange Server 2010 со всеми ролями. Как и все другие наши серверы, этот работает в виртуальной машине на базе VMware vSphere 4.1 и располагает четырьмя виртуальными процессорами. Этот скриншот был сделан в тот период, когда нагрузка на сервер была совсем не высока.
Начнем с общего обзора консоли. Большую часть окна занимают статистические показатели, о которых я подробно расскажу ниже. Я не буду повторяться: если показатель присутствует в нескольких местах, я упомяну его только в первый раз.
Процессы
В разделе «Процессы» (Processes) перечислены все запущенные процессы, использующие ресурсы центрального процессора. В списке показано имя исполняемого файла и ряд связанных с ним статистических показателей.
• «Образ» (Image) – имя исполняемого файла. Это имя процесса, использующего ресурсы ЦП.
• «ИД процесса» (PID) – идентификатор процесса. Может пригодиться для управления процессами с использованием других утилит или для поиска процессов в Диспетчере задач (Task Manager).
• «Описание» (Description) – короткое описание, объясняющее назначение процесса.
• «Состояние» (Status) – состояние выполнения процесса: чаще всего «Выполняется» (Running), иногда – «Прерван» (Terminated), если процесс больше не выполняется.
• «Потоки» (Threads) – количество активных потоков. Поток – это единица обработки.
• «ЦП» (CPU) – текущий процент загрузки ЦП процессом, другими словами, сколько ресурсов процессора выделено данному процессу.
• «Среднее для ЦП» (Average CPU) – среднее потребление ресурсов ЦП процессом за последние 60 секунд. Этот показатель позволяет оценить состояние системы за последнюю минуту и в данный момент.
Раздел «Процессы» очень полезен для диагностики – он позволяет быстро оценить текущее состояние системы. Еще один вариант применения – нажать на зависшем процессе правой кнопкой мыши и выбрать опцию «Анализ цепочки ожидания» (Analyze Wait Chain, рис. B). По результатам анализа выводится отчет (рис. C).
Службы
В разделе «Службы» (Services) перечислены все запущенные службы. На рис. A, как можно заметить, перечислены только службы, связанные с двумя выделенными процессами. Это позволяет отследить взаимосвязи процессов и служб, что может пригодиться при диагностике. Кроме того, на любой службе можно нажать правой кнопкой мыши для остановки или перезапуска.
• «Группа» (Group) – группа, к которой принадлежит служба. Некоторые службы работают вместе в группах.
Связанные дескрипторы
Возникала ли у вас хоть раз потребность выяснить, каким процессом открыт файл? Раздел Монитора ресурсов «Связанные дескрипторы» (Associated Handles) предназначен как раз для этого. Дескрипторы – это указатели, которые ссылаются на файлы, ключи реестра, каталоги и т. д.
В поле «Поиск дескриптора» (Search Handles) введите имя файла или путь – и получите список процессов, его использующих. Это особенно удобно при работе со службами, использующими множество файлов, например, svchost. На рис. E показано, как данная функция помогает проредить массу процессов svchost. В этой таблице можно нажать правой кнопкой мыши на любом файле svchost и завершить данный конкретный процесс.
• «Тип» (Type) – тип дескриптора. О типах дескрипторов подробно рассказывается в статье Марка Руссиновича (Mark Russinovich) на сайте TechNet.
• «Имя дескриптора» (Handle Name) – имя дескриптора, связанного с выбранным процессом. Имя можно использовать для поиска связанных файлов или ключей реестра.
Связанные модули
Модули – это вспомогательные файлы или программы, например, библиотеки DLL, используемые процессами для выполнения своих задач. Информация из раздела «Связанные модули» (Associated modules) может пригодиться для более глубокого анализа потенциальных проблем, связанных со снижением производительности.
• «Имя модуля» (Module name) – имя модуля, загруженного выбранными процессами.
• «Версия» (Version) – версия файла для соответствующего модуля.
• «Полный путь» (Full Path) – полный путь к используемому модулю.
Графики
В правой части окна расположены графики, представляющие различные показатели производительности центрального процессора.
• «ЦП – Всего» (CPU – Total) – отображает два показателя, представленные синими прямыми и зеленой кривой. Синяя прямая показывает общую вычислительную мощность процессора (частоту ЦП), доступную системе, а зеленая кривая – текущее использование этих ресурсов. Монитор ресурсов доступен в разных версиях Windows, и многие современные компьютеры оснащаются процессорами, которые способны снижать собственную частоту для экономии энергии и уменьшения температуры. При таком снижении частоты ЦП синяя прямая опускается, а зеленая кривая корректируется в соответствии с новыми условиями.
• «Использование ЦП службами» (Service CPU usage) – показывает, сколько ресурсов ЦП выделено фоновым службам и процессам.
• «ЦП 0 – ЦП 3» (CPU 0 – CPU 3) – показывает, сколько ресурсов каждого ядра процессора используется. Некоторые ЦП обозначены как припаркованные (Parked) – это значит, что они временно отключены, поскольку для них пока нет работы. Скриншоты для этой статьи были сделаны в нерабочее время на каникулах, так что наш Exchange к тому моменту пару месяцев простаивал.
В заключение
Вкладка «ЦП» в Мониторе ресурсов предоставляет массу полезной информации о ключевых показателях производительности центрального процессора.